今日推薦開源項目:《指南 shepherd》
今日推薦英文原文:《10 Mistakes You Should Avoid as a Web Developer》
(這裡放日報封面) (請檢查,本文勾上了且只勾了《開源日報》這一個分類,請檢查,有添加文章 Tag,請檢查,有添加文章摘要,請檢查,有添加特色圖像,有添加bigger圖片,有選中頭圖「布局設置」為佔滿屏幕的那張「第3張」) (請檢查,預覽時候,所有圖片和文字顯示正常,且勾上了百度熊掌號-原創提交) (請檢查,本文的信息已經添加到 https://pm.openingsource.org/projects/daily/wiki日報摘要里,每個月的摘要信息單獨發一個page,格式參照 https://openingsource.org/daily-index/2018-5/,標題,URL,正文等格式均需保持一致) (檢查上述都完成之後,請刪掉括弧里的字,包括這一句,每天發布時間為早晨8點左右)
今日推薦開源項目:《指南 shepherd》傳送門:GitHub鏈接
推薦理由:一個用於製作瀏覽器中教程功能的 JS 庫。如果你的頁面需要準備一個教程的話,比起直接寫文字用這個會有更好的表現。為了在其他框架上能夠更好的使用,它還提供了對諸如 React,Vue 等框架的包裝器,讓其能更簡單的應用於框架中。
今日推薦英文原文:《10 Mistakes You Should Avoid as a Web Developer》作者:Subhajit Dutta
原文鏈接:https://medium.com/@ajay.dutta94/10-mistakes-you-should-avoid-as-a-web-developer-c4ad4d2570f6
推薦理由:有些時候這些錯誤並不只會發生在 Web 開發者身上
10 Mistakes You Should Avoid as a Web Developer
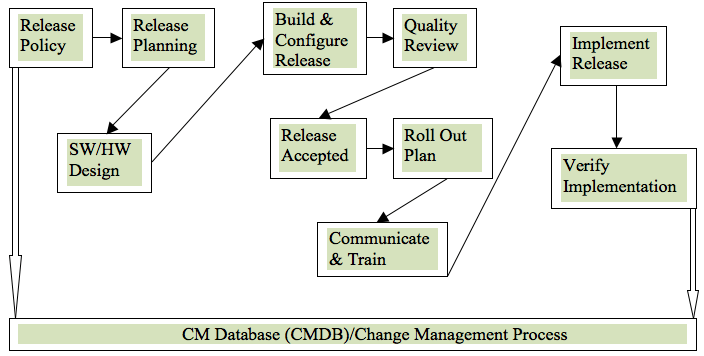
Release process
We as a developer always try to follow best practices while writing code, developing websites or developing an Android or IOS app.
Sometimes development workflow becomes too complex and with a lot of tools and techniques out there, it becomes confusing for a developer to choose from various development patterns.
Here are some mistakes we generally make while delivering or developing web-based products…
Not tracking errors in production
I feel like this is the most ignored point of web development.We often test our code with staging and production environment before deploying to production. We also write automated tests and follow TDD pattern just to make sure it does not crash in production and forget about tracking error/bugs in live production websites.
There are various tools out there to track bugs/errors depending upon language or framework you use for developing a website.
For JS error tracking you can use
- Sentry
- TrackJS
- Rollbar
Making Changes directly on the Server
Yaa, I know, we all do it or have done it. When we need a small and critical change or a critical bug fix in the website, we often end up editing code directly in the server. Changes that we make in the server, if not pushed to repo, may be lost in the next deployment. That』s the double work for a developer to write the same code again in the local system.Downtime while deploying
While deploying code to the server, it is very much possible that the server goes offline in case of typical deployment policies. That can be super annoying for a user if the website stops working while he/she is using it. So, it is always recommended to use a deployment policy that deploys the code to the server without stopping the website.Not Worrying about security in the code
I have seen many developers doing this. We often hide secret credentials like API keys, client secrets or other secret credentials somewhere in the code itself. If that is on the client side, it can be super risky.It is always recommended to store secret credentials in a place where it is out of reach of visitors. Eg. We can use encrypted storage or ENV variables.
Not Notifying Team Members
The typical developer is always busy working on new features and making changes to their code. Sometimes they have to wait until the deployment finishes to see if the reflected changes are working as they should.Having a poor communication channel and not notifying everyone on the team about a finished or failed deployment is a huge mistake. Developers lose their focus while waiting for a notification they』ll never get.
Using The Same Environment for Development and Production
Everyone loves simplicity. So why bother with the added complexity of separate environments for development and production? Pushing changes directly to a production server is like playing with fire. Sooner or later, you』re bound to get burned. Now, the excuse for those using a manual workflow is that deploying to two different platforms takes too much time. But that』s just another reason to automate!Having No Backup Plan
Having a backup plan is like having insurance. If you wait until you need it, it will be too late! If a change that』s deployed to the production server actually breaks the server, you』re in trouble if you have no backup plan. You』ll need to start at the beginning, successively performing new deployments to get everything back to a normal state. That takes a lot of time and resources; significantly more than rolling back to a prior deployment, which those of us with a backup plan can perform.Not using Caching on the client side
No one wants to wait (and wait and wait) for your site to load. So, it is also one of the important things to keep in mind while developing a website that we use fast loading mechanism like Caching and Lazy Loading.- Caching: Make sure you cache static assets like CSS, JS, and images in the browser storage so that browsers do not download it every time from the server.
- Lazy Loading: Always try to lazy load external scripts or images only when they are required. Code Lazy Loading can be achieved through Webpack and progressive image loading can be achieved through 「intersection observer」
Performing Manual Deployments
Manual deployments are time consuming, complex and frequently cause great trouble. A couple of inadvertent keystrokes made by an inexperienced developer and bang! You』ve got yourself the virtual equivalent of a nuclear meltdown. All the time you thought you were saving is instantly gone as you rush to put everything back together again.Poorly Communicating When a Deployment Occurs
It』s always a good idea to let your team know when you』re ready to deploy. That way they can be available if additional support is required or the changes don』t perform as expected. Manual notification isn』t ideal because it』s susceptible to error, and using different platforms for communication and notifications unnecessarily complicates matters.Conclusion: Ultimately, Website Deployment on Production in Sitecore must ensure that the step — by — step approach is properly followed using the full potential of development, quality assurance, staging and production. To complete the cycle, always verify the release before switching from disaster recovery to live.
下載開源日報APP:https://openingsource.org/2579/
加入我們:https://openingsource.org/about/join/
關注我們:https://openingsource.org/about/love/
