每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 https://t.me/OpeningSourceOrg
今日推荐开源项目:《Majestic》GitHub地址:https://github.com/Raathigesh/majestic
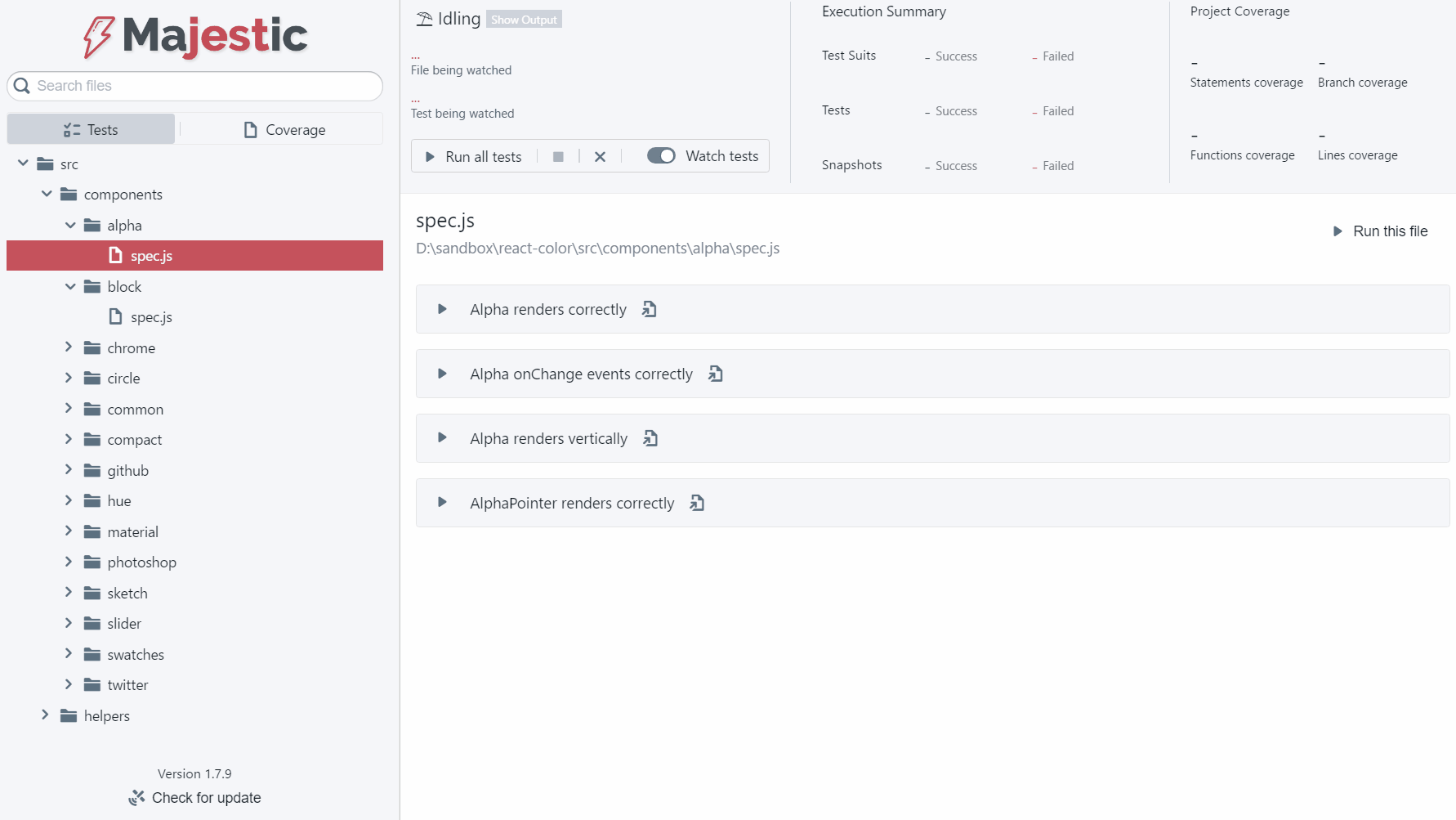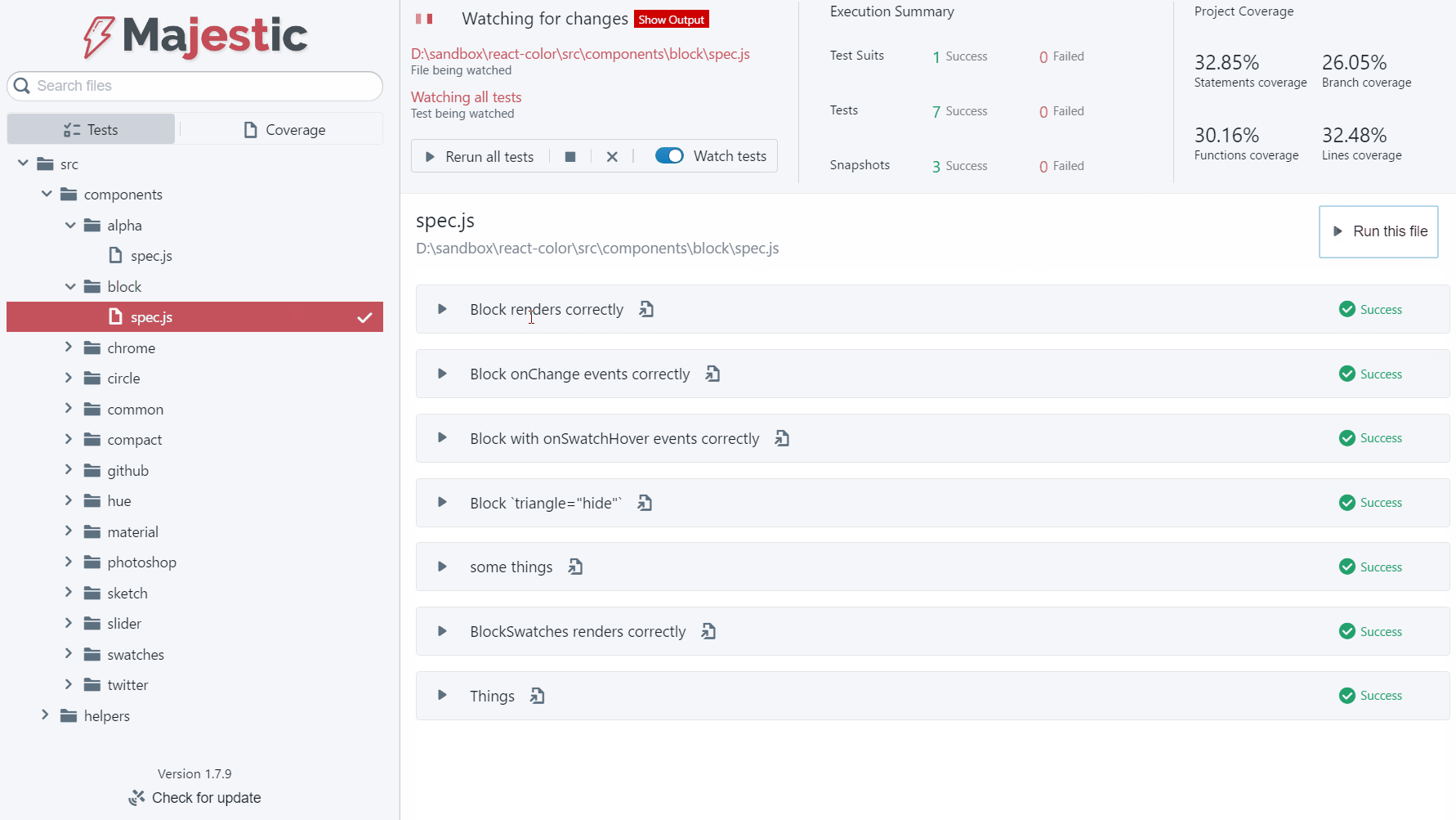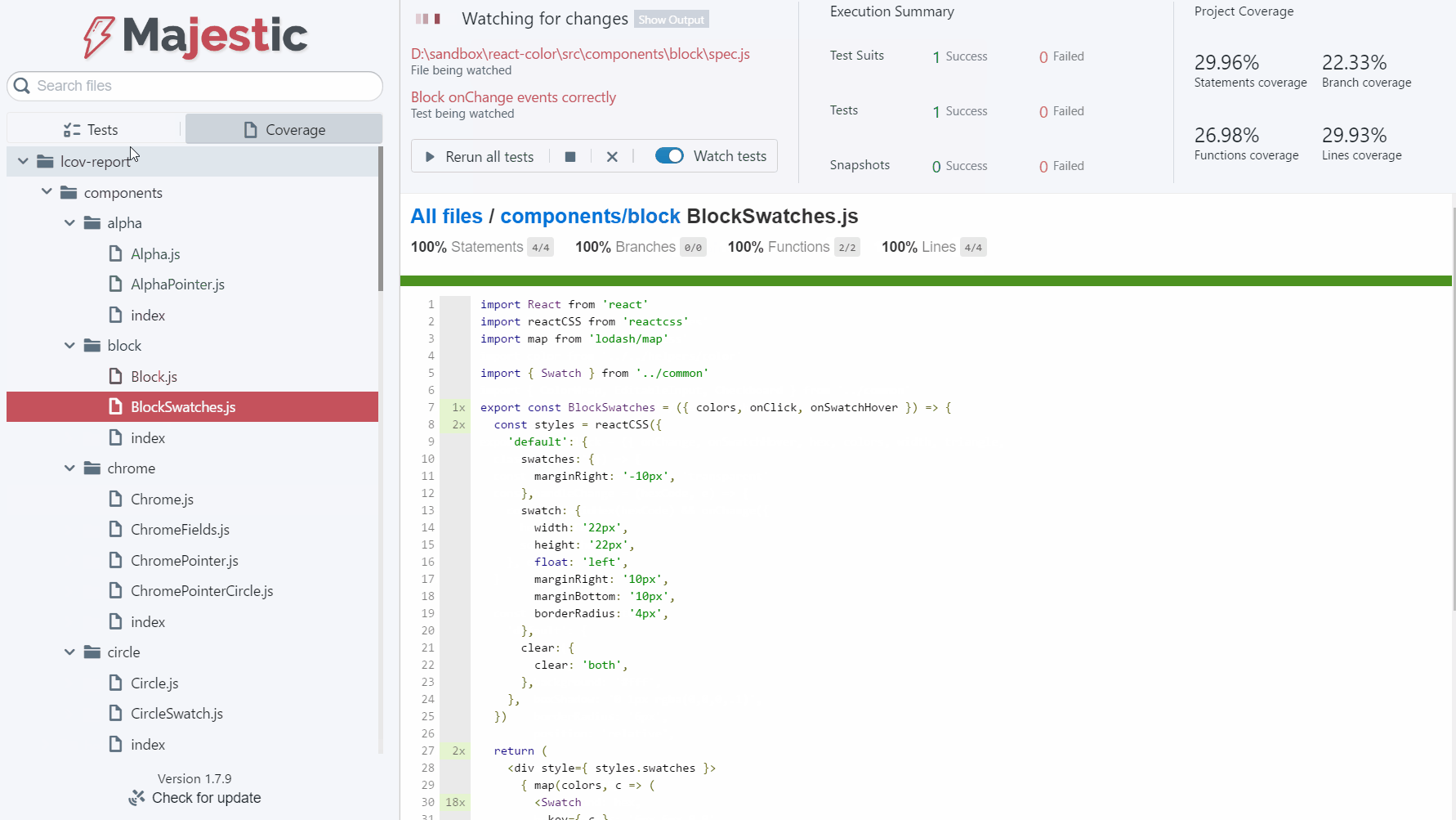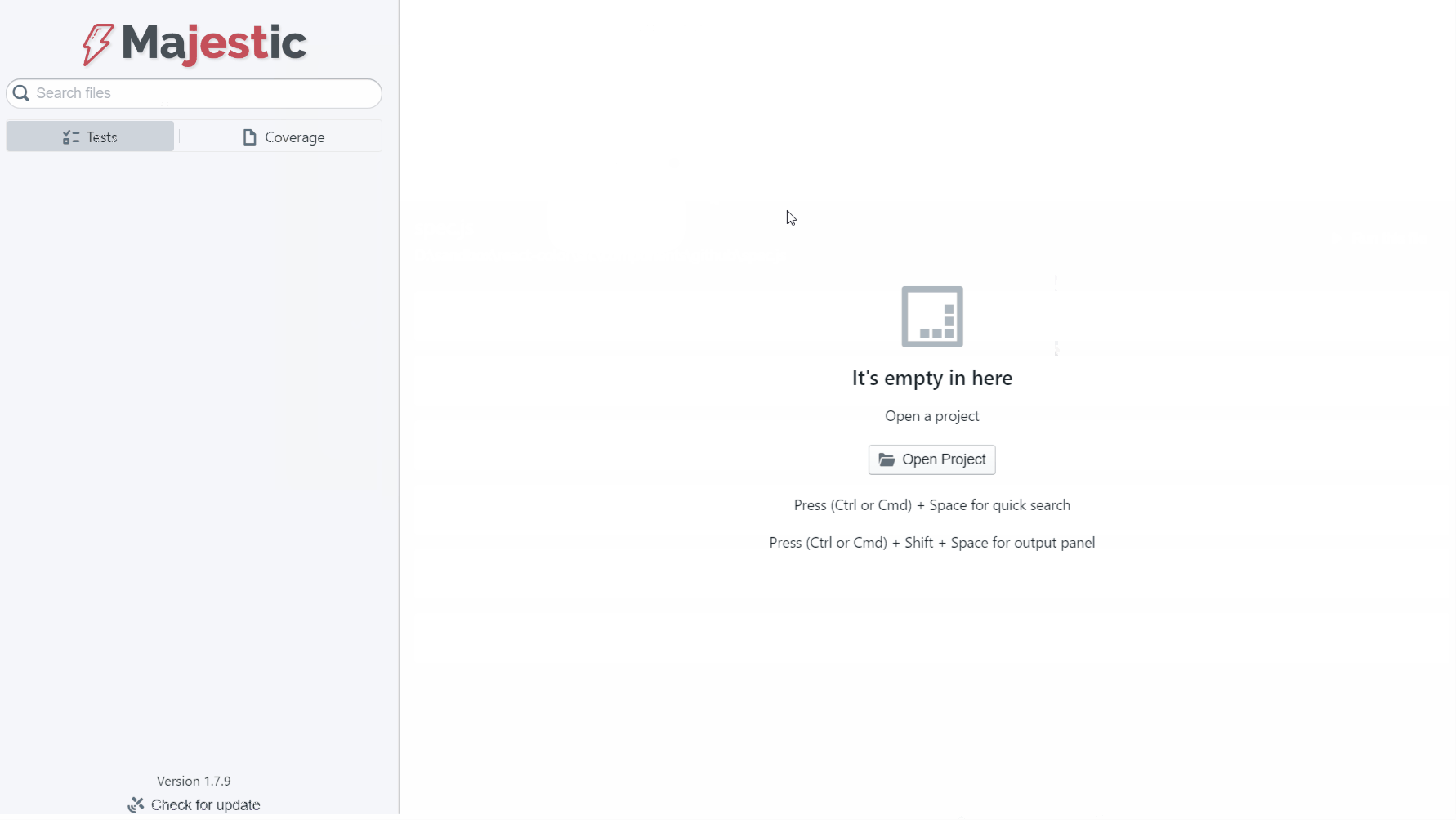
推荐理由:Majestic是一个电子应用程序,提供了一个用Jest运行测试的UI。Jest CLI本身提供了当今最好的测试体验之一,但Majestic试图通过提供一个丰富的用户界面来在开发/测试循环期间扩展它。

特征:
• 通过点击运行整个项目,文件或特定的测试
• 观看整个项目,文件或测试
• 点击更新特定的快照“
• 内联覆盖报告
• 支持打字稿项目
• 支持Create-React-App开箱即用
• 快速搜索,搜索您的所有测试(It)声明
• 失败摘要在单个屏幕中显示所有测试失败。跨多个文件出现故障时很有用。
• 点击一个按钮,在您的编辑器中找到一个特定的测试
如果你有一个外部的jest配置文件,你应该有一个指向文件的jestConfig键,package.json如下所示:
{
“ name ”:“ my-awesome-proj ”,
“ version ”:“ 0.1.0 ”,
“ description ”:“ .. ”,
“ jestConfig ”:“ ./jest-custom.config.js ”
}
今日推荐英文原文:《Using Deep Learning to Understand Your Source Code》作者:Jesus Rodriguez
原文链接:https://medium.com/@jrodthoughts/using-deep-learning-to-understand-your-source-code-28e5c284bfda
推荐理由:使用机器学习来理解你的源代码?正是没错。你知道你的程序出错,但是不知道哪里出错?想找个人帮帮忙?嘿嘿!
Using Deep Learning to Understand Your Source Code
This should be a familiar experience to any programmer. You are immersed writing code in a static language like C# or Java, you have happily written a few hundred lines of this beautiful algorithm and then you press compile hoping to see the results of your great work. To your frustration, the compiler outputs an error message in bold red lines indicating that you missed a semicolon in line 17. At that point, you can’t avoid thinking why the stupid compiler doesn’t just add the semicolon to the end of line 17 and move on instead of telling you. Seriously, how hard could that be? Well, it turns out its pretty hard. The reason for the compiler’s frustrating behavior is that code interpreters and compilers today and extremely efficient analyzing the syntactic aspects of a problem but very limited when comes to understand the semantics of the program or our intentions as a programmer.
Many bugs in a program are not solely derived from the syntax of the program due to the higher level semantic aspects. Consider the following code snippet that should indicate an agent to turn right. While it is very obvious to a programmer that the code is wrong as it us using the left angle to turn right, mainstream compilers are completely incapable to detect that flaw.
When a programmer looks at a specific source code, it seems more than instructions and functions and it starts forming an understanding of the goals and functionality of the program. Wouldn’t it be great if compilers were able to formulate a similar level of understanding? The irony is that recent advancements in deep learning areas such as natural language understanding(NLU) allow artificial intelligence(AI) agents to understand highly complex communication structures such as human conversations while we still can’t figure out highly structured texts such as computer programs.
Recently, Microsoft Research published a paper that proposes a technique that combines NLU techniques with mathematical logic to detect semantically-related bugs in source code. The key idea of the technique is to form a semantic representation of source code that complements its syntactic structure in order to detect more abstract errors.
Titled “Learning to Represent Programs with Graphs”, the Microsoft Research paper introduces a deep learning method that transform a specific source code into a graph structure. The nodes of the graph include the tokens of the program (that is, variables, operators, method names, and so on) and the nodes of its abstract syntax tree (elements from the grammar defining the language syntax such as If Statement). The program graph contains two different types of edges: syntactic edges, representing only how the code should be parsed, such as while loops and if blocks; and semantic edges that are the result of simple program analyses.
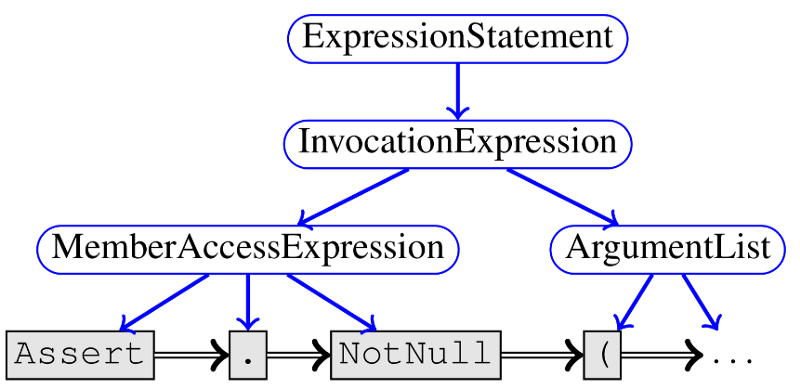
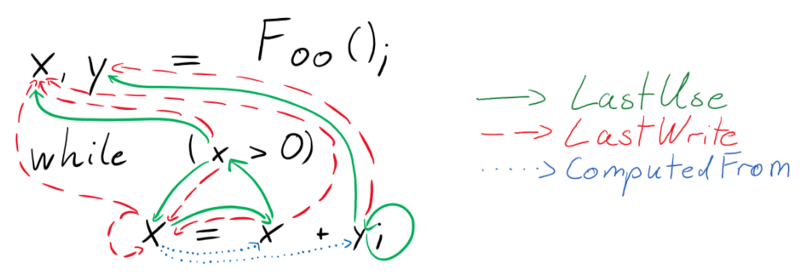
Having semantic edges allows the deep learning model to represent all sorts of high level knowledge constructs that resemble the way programmers analyze a specific source code. For instance, semantic edges such as “LastUse” connect a variable to the last time it may have been used in program execution (which in the case of loops can be later in the source code), “LastWrite” edges connect a variable to the last time it was written to, or as “ComputedFrom” edges connect a variable to the values it was computed from. From that perspective, a large group of semantic edges can help to simulate the human interpretation process of a computer program.
In order to validate their technique, the Microsoft researchers focused on two specific types of semantic errors. The VARMISUSE task is focused on detecting variable misuses in code is a task that requires understanding and reasoning about program semantics. To successfully tackle the task one needs to infer the role and function of the program elements and understand how they relate. For example, given the following program, the task is to automatically detect that the marked use of clazz is a mistake and that first should be used instead.
var clazz=classTypes["Root"].Single() as JsonCodeGenerator.ClassType; Assert.NotNull(clazz); var first=classTypes["RecClass"].Single() as JsonCodeGenerator.ClassType; Assert.NotNull( clazz ); Assert.Equal("string", first.Properties["Name"].Name); Assert.False(clazz.Properties["Name"].IsArray);
Similarly, the VARNAMING task corrects infers the correct variable name based on a specific syntaxtic representation of a source code. For instance, the following example from the C# Roslyn compiler detected incorrect uses of the parameter filepath and the field _filePath, which are easily mistaken for each other.

The use of Program Graphs are not only an interesting theoretical exercise but it proven to be more efficient than many alternatives in the deep learning space. The Microsoft team conducted experiments analyzing over 2.9 million lines of source code and the new technique yielded substantially better results that more traditional methods such as bidirectional recurrent neural networks. Although the methods are highly experimental, program graphs seem to be a step towards making compilers are intelligent as human programmers.
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 https://t.me/OpeningSourceOrg
