今日推薦開源項目:《人工智慧 Google AI Research》
今日推薦英文原文:《Google Hash Code 2020: How we Took 98.5% of the Best Score》

今日推薦開源項目:《人工智慧 Google AI Research》傳送門:GitHub鏈接
推薦理由:該項目包含Google AI Research發布的代碼。Google AI 致力於推動該領域的最新發展,將AI應用於產品和新領域,並開發工具以確保每個人都可以使用AI。附上Google AI 的官方網站:https://ai.google/research
今日推薦英文原文:《Google Hash Code 2020: How we Took 98.5% of the Best Score》作者:Yelysei Lukin
原文鏈接:https://medium.com/better-programming/google-hash-code-2020-how-we-took-98-5-of-the-best-score-e5b6fa4abc1b
推薦理由:前不久 Google Hash Code 的線上資格賽開賽,本文記錄了一個烏克蘭團隊的解題經歷。
Google Hash Code 2020: How we Took 98.5% of the Best Score
How we came in 53rd in Ukraine and 530th in the world

(Photo by Mitchell Luo on Unsplash)Since we didn』t get a chance to participate in this year』s Google Hash Code, we decided to try our best in the extended round. Here』s the result: 530th in the world ranking and 53rd in Ukraine.
What is Google Hash Code?
Google has been organizing a competition for programmers since 2016 called Hash Code. Teams of two to four people can participate in the competition, where they have to solve an optimization problem. Every year it attracts thousands of people from all over the world.It has two rounds: main and extended. The main round continues only for four hours, while the extended one can go on for up to two weeks. Of course, the extended round does not count on the scoreboard, but it』s still a good chance to check your knowledge and skills.
As we mentioned, we didn』t have a chance to participate in the main round, but maybe our solution will be interesting for you. Or perhaps it will push you to try to implement your own solution.
This Year』s Task Description
This year the participants were given the problem of scanning books from different libraries.You have to choose books with the biggest score, from libraries which first have to sign up. This must be done within the given deadline. The same books can be available in more than one library, but you can get a score for each book only once. Furthermore, each library can provide different numbers of books per day.
This is the initial data that we have:
- Only one library can be signing up at one moment.
- Only a signed up library can provide you with books for scanning.
- You have a total deadline.
- Your goal is to get the highest possible score of all provided books.
It may sound a little complicated, at least in our words! Hopefully, this image will help you to get to the bottom of the situation:
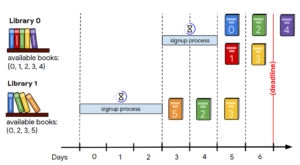 If you haven』t solved this issue yet, we suggest you postpone reading the rest of this piece and try to do it on your own first.
If you haven』t solved this issue yet, we suggest you postpone reading the rest of this piece and try to do it on your own first.Our Solution
Analyzing the task description, we came to the conclusion that there』s basically only one issue that we needed to solve: Each time the sign-up process is empty, we have to find the most suitable library that we will pass to sign up.In order to find this library we decided to evaluate them by the following criteria: two positive — the score of library books and the number of books we can scan per day; and one negative — how many days are required to sign up for a library.
The first algorithm that we stopped at is pretty straightforward. It basically calculates how much score the library will produce if we start the sign up at this moment.
- Сalculate how many days will remain after the sign up is finished.
- Multiply by the number of books scanned per day.
- Sort books by their score and get top books.
- The cumulative score of scanned books is the library value.
Here are the results:
 This solution was pretty good but still far from perfect. So we kept trying.
This solution was pretty good but still far from perfect. So we kept trying.After further brainstorming, we figured out that the negative criterion (days count to sign up a library) is not represented properly in our equation.
Among many ways to introduce this criterion in our formula (define some coefficients for criteria, etc.), we selected the following one — divide the calculated value by the number of days to sign up. This way we get the ratio between the good input and the bad one.
The results that we received were pretty astonishing and they turned out to be just 1.5% less than the best results at that moment.
 Here』s our source code (do not judge us, we did it in a hurry!):
Here』s our source code (do not judge us, we did it in a hurry!):const fs = require('fs');
const files = {
a: {
input: 'tasks/a_example.txt',
output: 'results/a_result.txt',
},
b: {
input: 'tasks/b_read_on.txt',
output: 'results/b_result.txt',
},
c: {
input: 'tasks/c_incunabula.txt',
output: 'results/c_result.txt',
},
d: {
input: 'tasks/d_tough_choices.txt',
output: 'results/d_result.txt',
},
e: {
input: 'tasks/e_so_many_books.txt',
output: 'results/e_result.txt',
},
f: {
input: 'tasks/f_libraries_of_the_world.txt',
output: 'results/f_result.txt',
},
};
const file = fs.readFileSync(files[process.env.FILE].input, 'utf-8');
const result = file.split('\n').map((item) => item.split(' '));
const readyLibraries = [];
const set = {
booksNumber: parseInt(result[0][0]),
deadLine: parseInt(result[0][2]),
booksScore: [...result[1].map((it) => parseInt(it, 10))],
libraries: [],
};
for (let i = 0; i < result[0][1]; i++) {
const firstRow = result[i * 2 + 2];
const secondRow = result[i * 2 + 3];
set.libraries.push({
daysToSignUp: parseInt(firstRow[1]),
scanPerDay: parseInt(firstRow[2]),
books: [
...secondRow
.map((it) => parseInt(it, 10))
.sort((a, b) => set.booksScore[b] - set.booksScore[a]),
],
});
}
let signUpLibrary = null;
for (let i = 0; i < set.deadLine; i++) {
if (!signUpLibrary) {
signUpLibrary = findLibraryToSignUp(i);
}
if (signUpLibrary) {
signUpLibrary.daysToSignUp--;
if (signUpLibrary.daysToSignUp === 0) {
const scannedBooks = set.libraries[signUpLibrary.id].books.slice(0, signUpLibrary.booksCount);
readyLibraries.push({
id: signUpLibrary.id,
books: scannedBooks,
});
set.libraries[signUpLibrary.id] = undefined;
signUpLibrary = null;
removeDuplicates(scannedBooks);
}
}
}
function findLibraryToSignUp(currentDay) {
const availableLibraries = set.libraries
.map((library, index) => (library !== undefined ? {
id: index,
value: 0,
daysToSignUp: library.daysToSignUp,
} : undefined))
.filter((item) => item !== undefined);
availableLibraries.forEach((library) => {
const activeDays = set.deadLine - currentDay - library.daysToSignUp;
const trueLibrary = set.libraries[library.id];
const scannedBooks = Math.min(
activeDays * trueLibrary.scanPerDay,
trueLibrary.books.length,
);
library.booksCount = scannedBooks;
trueLibrary.books.slice(0, scannedBooks).forEach((id) => {
library.value += set.booksScore[id];
});
library.value /= library.daysToSignUp;
});
const sorted = availableLibraries.sort((a, b) => {
if (b.value === a.value) {
return b.daysToSignUp - a.daysToSignUp;
}
return b.value - a.value;
});
return sorted[0];
}
function removeDuplicates(booksToRemove) {
set.libraries.forEach((library) => {
if (library) {
library.books = library.books.filter(
(book) => !booksToRemove.some((book1) => book1 === book),
);
}
});
}
let results = 0;
readyLibraries.forEach((lib) => {
lib.books.forEach((book) => {
results += set.booksScore[book];
})
});
console.log(`score: ${results}`);
const finalResult = [readyLibraries.length];
readyLibraries.forEach((library) => {
finalResult.push(`${library.id} ${library.books.length}`);
finalResult.push(library.books.join(' '));
});
fs.writeFileSync(files[process.env.FILE].output, finalResult.join('\n'));
What We Learned From This Experience
- Think algorithmically
- Find the root of the problem — even if the task looks complicated at first glance, the real issue may be pretty easy.
- Consider all variables of the equation.
- Don』t stop improving results — if something works, it doesn』t mean it can』t work better.
- Use TypeScript instead of JavaScript. We spent a lot of time debugging JavaScript issues that could have been prevented by using TypeScript.
Credits to team members:
Yelysei Lukin (LinkedIn)Oleh Zaporozhets (LinkedIn)
下載開源日報APP:https://openingsource.org/2579/
加入我們:https://openingsource.org/about/join/
關注我們:https://openingsource.org/about/love/
