今日推薦開源項目:《Brackets》
今日推薦英文原文:《What Is Active Learning?》

今日推薦開源項目:《Brackets》傳送門:GitHub鏈接
推薦理由:Brackets是HTML,CSS和JavaScript 內置的現代開源代碼編輯器,用於HTML,CSS和JavaScript。 這款編輯器具有簡潔的UI界面,使得上手更加輕鬆;有強大的同步功能,使得您的代碼能與瀏覽器同步;並且它是一款開源的軟體,您可以將其打造成為您的個性化編輯器。
今日推薦英文原文:《What Is Active Learning?》作者:DANNY SHAPIRO
原文鏈接:https://blogs.nvidia.com/blog/2020/01/16/what-is-active-learning/
推薦理由:主動學習是一種用於機器學習的訓練數據選擇方法,可以自動找到這些多樣化的數據。它只需花費人類整理時間的一小部分即可構建更好的數據集。主動學習與當下火熱的自動駕駛有著密切的聯繫,通過相關文章的閱讀,我們能更好的了解這些前沿的科技。
What Is Active Learning?
Finding the right self-driving training data doesn』t have to take a swarm of human labelers.
Reading one book on a particular subject won』t make you an expert. Nor will reading multiple books containing similar material. Truly mastering a skill or area of knowledge requires lots of information coming from a diversity of sources.The same is true for autonomous driving and other AI-powered technologies.
The deep neural networks responsible for self-driving functions require exhaustive training. Both in situations they』re likely to encounter during daily trips, as well as unusual ones they』ll hopefully never come across. The key to success is making sure they』re trained on the right data.
What』s the right data? Situations that are new or uncertain. No repeating the same scenarios over and over.
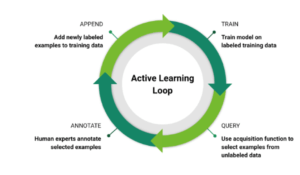
Active learning is a training data selection method for machine learning that automatically finds this diverse data. It builds better datasets in a fraction of the time it would take for humans to curate.
It works by employing a trained model to go through collected data, flagging frames it』s having trouble recognizing. These frames are then labeled by humans. Then they』re added to the training data. This increases the model』s accuracy for situations like perceiving objects in tough conditions.
Finding the Needle in the Data Haystack
The amount of data needed to train an autonomous vehicle is enormous. Experts at RAND estimate that vehicles need 11 billion miles of driving to perform just 20 percent better than a human. This translates to more than 500 years of nonstop driving in the real world with a fleet of 100 cars.And not just any driving data will do. Effective training data must contain diverse and challenging conditions to ensure the car can drive safely.
If humans were to annotate this validation data to find these scenarios, the 100-car fleet driving just eight hours a day would require more than 1 million labelers to manage frames from all the cameras on the vehicle — a gargantuan effort. In addition to the labor cost, the compute and storage resources needed to train DNNs on this data would be infeasible.
The combination of data annotation and curation poses a major challenge to autonomous vehicle development. By applying AI to this process, it』s possible to cut down on the time and cost spent on training, while also increasing the accuracy of the networks.
Why Active Learning
There are three common methods to selecting autonomous driving DNN training data. Random sampling extracts frames from a pool of data at uniform intervals, capturing the most common scenarios but likely leaving out rare patterns.Metadata-based sampling uses basic tags (for example, rain, night) to select data, making it easy to find commonly encountered difficult situations, but missing unique frames that aren』t easily classified, like a tractor trailer or man on stilts crossing the road.
 Caption: Not all data is created equal. Example of a common highway scene (top left) vs. some unusual driving scenarios (top right: cyclist doing a wheelie at night, bottom left: truck towing trailer towing quad, bottom right: pedestrian on jumping stilts).
Caption: Not all data is created equal. Example of a common highway scene (top left) vs. some unusual driving scenarios (top right: cyclist doing a wheelie at night, bottom left: truck towing trailer towing quad, bottom right: pedestrian on jumping stilts).Finally, manual curation uses metadata tags combined with visual browsing by human annotators — a time-consuming task that can be error-prone and difficult to scale.
Active learning makes it possible to automate the selection process while choosing valuable data points. It starts by training a dedicated DNN on already-labeled data. The network then sorts through unlabeled data, selecting frames that it doesn』t recognize, thereby finding data that would be challenging to the autonomous vehicle algorithm.
That data is then reviewed and labeled by human annotators, and added to the training data pool.
 Active learning has already shown it can improve the detection accuracy of self-driving DNNs over manual curation. In our own research, we』ve found that the increase in precision when training with active learning data can be 3x for pedestrian detection and 4.4x for bicycle detection relative to the increase for data selected manually.
Active learning has already shown it can improve the detection accuracy of self-driving DNNs over manual curation. In our own research, we』ve found that the increase in precision when training with active learning data can be 3x for pedestrian detection and 4.4x for bicycle detection relative to the increase for data selected manually.Advanced training methods like active learning, as well as transfer learning and federated learning, are most effective when run on a robust, scalable AI infrastructure. This makes it possible to manage massive amounts of data in parallel, shortening the development cycle.
下載開源日報APP:https://openingsource.org/2579/
加入我們:https://openingsource.org/about/join/
關注我們:https://openingsource.org/about/love/
