今日推荐开源项目:《三语精通之四 less.js》
今日推荐英文原文:《Developers Should Be (a Little Bit) Reckless》

今日推荐开源项目:《三语精通之四 less.js》传送门:GitHub链接
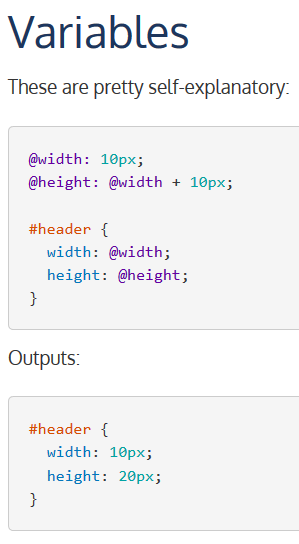
推荐理由:虽然不管是在现实世界还是虚拟世界里同时掌握中日英这样三种现实语言的人并不多,但是 web 开发里掌握 html+js+css 也算是一种三语精通——虽然在这之上还有第四第五种。这个项目是一种动态样式表语言,为 css 引入了基本编程语言里常见的变量和计算等,尽管在这之上需要额外的配置和编译,但是以此为代价换来了免去的重复作业和更好的可读性,在诸如样式表层层叠叠过于细致等等的时候可以换来不少好处。
今日推荐英文原文:《Developers Should Be (a Little Bit) Reckless》作者:Tom Feron
原文链接:https://medium.com/better-programming/developers-should-be-a-little-bit-reckless-3d2521ad9641
推荐理由:所谓系统,总归有要出问题的时候,预防它和修好它都一样重要
Developers Should Be (a Little Bit) Reckless
Why you should embrace and plan for chaos
Any software project has to make a trade-off between building new features and making the current system more resilient and easier to maintain.Too often, management pushes for new features and, before you know it, you end up with a big ball of mud where any change takes ages due to the accidental complexity that gathered over time.
Complexity leads to bugs and soon enough, changes become risky. Developers get terrified at the idea of shipping anything but trivial things. Badly needed improvements to the codebase are too involved and, therefore, don’t get done. This is a vicious circle you don’t want to get into.
The key to solving this issue is building resilient systems.
Resilient systems allow for innovation to happen. If services are unlikely to crash or even perform badly when mistakes are made, the risk associated with code changes is reduced and, therefore, new features and refactoring are easier to ship so you can escape the vicious circle.
There are two ways of making software development more resilient: putting the responsibility onto people or relying on machines.
The first approach requires developers to follow guidelines and procedures, to double-check everything before they merge something new. This can put a lot of pressure on them.
You might have seen or experienced this yourself: someone avoids making a big change for fear of breaking something and being blamed for it.
Alternatively, you can see bugs and outages as things that were allowed by the systems in place. It is not the responsibility of the person who shipped it anymore. Your system is the one that needs to change.
Virtuous and vicious circles are two sides of the same coin. The situation gets a lot more enviable when computers are responsible for making sure the services are running properly.
As the confidence in the ability of the system to prevent or fix errors grows, developers and other people in the company will become more reckless.
This is a good thing. Having a safety net allows you to be bold and experiment with new things. It fosters innovation and increases the speed at which improvements can be shipped.
Sure, it might break now and then but overall resilience increases as a result.
Antifragile Systems
In his book Antifragile, Nassim Taleb develops the concept of antifragility as being different from resilience. Antifragile systems gain from shocks.A software project throughout its lifetime is an evolving creature. New features come in, bugs are introduced and others are fixed, the code is refactored.
In that sense, we should aim to build antifragile systems. That is, problems should lead us to improve the resiliency of the system over time.
Trying to eliminate the problems upfront by requiring developers to be disciplined and meticulous is doing the project a disservice since it does not lead to improvements to prevent these mistakes in the first place.
Embrace the chaos and build antifragile systems.
How Do I Start?
If the project is brand new, it’s easy. Allow yourself and others to be reckless by not blaming anyone and by treating problems in production as learning experiences to improve resilience.But what about projects that are already there? They might be brittle and any downtime is expensive.
In that case, start by establishing a list of all the ways production can break. Look back at the past and see if there have been problems that could happen again.
This should be a living document where new problems are added as they arise. If a potential issue is caught during code review, it should be added to that document as well.
The next step is to decide what the best way is for you to prevent these things from happening and to prioritize them.
If you don’t know what to prioritize, try assigning a value from one to three to each item on your list for severity — how much it would impact the company and how hard it is to solve — and likelihood — how likely it is to happen.
The product of the two determines which ones to tackle first.
And finally, stop blaming people for outages and phrase post-mortems in terms of why the system allowed it to happen in the first place and how they should be fixed.
How Do I Avoid (Too Much) Chaos?
Being reckless increases the probability of breaking something. Even if it helps pointing you to what needs to be fixed, it certainly should not happen too much.In their books (available for free), Google’s SRE team introduces the concept of an error budget. In its simplest form, it could be the acceptable downtime over a week. The chapter Service Level Objectives is particularly interesting.
After the error budget has been consumed, changes to production should be postponed unless urgent. That way, you limit the amount of chaos you introduce.
Also worth noting is that Kubernetes has disruption budgets that can be leveraged for that purpose.
Chaos Engineering
The previous section was about limiting chaos, but what about increasing it a little bit?In addition to discovering new ways in which things can break you didn’t think of, it can help to set expectations for other teams and customers. This might be counter-intuitive but too stable a system is not necessarily good from a commercial point-of-view either.
What happens when you have a serious outage that lasts a couple of hours? If other teams and customers expect your service to always be up and responsive because it always has been so far, they probably haven’t catered for this scenario. It means trouble for them and, by extension, for you as well.
On the other hand, if they expect your service not to respond sometimes or for some requests to be slow, maybe they would have implemented a cache or better exception handling.
Taking the opposite point-of-view, you might have expectations about services that you consume which are not going to hold forever. Deliberately dropping or slowing down packages to and from a third-party service can force you to make your code more resilient to problems on their side.
Chaos engineering, introduced by Greg Orzell when he was working at Netflix, is:
“The discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.”The most notable tool for chaos engineering is ChaosMonkey which randomly kills virtual machines and containers in your environment.
If you are a service mesh or something similar, you might want to look into introducing errors and delays in the network. For example, Istio provides support for fault injection.
Conclusion
To keep momentum and foster innovation, developers should be free to explore new areas instead of stressing about breaking things.They should be allowed to be bold and reckless thanks to the safety nets provided by automated controls. This (limited) chaos, in turn, makes the system stronger over time.
This can only happen if everyone involved agrees on prioritizing work required to prevent problems from happening again when they do occur.
下载开源日报APP:https://openingsource.org/2579/
加入我们:https://openingsource.org/about/join/
关注我们:https://openingsource.org/about/love/

今天英文文章的意思是:写程序,得留条后路….