今日推荐开源项目:《workshop frontend-bootcamp》
今日推荐英文原文:《A Beginner’s Guide to Machine Learning》

今日推荐开源项目:《workshop frontend-bootcamp》传送门:GitHub链接
推荐理由:一个关于 web 基础知识的 workshop。第一天介绍了基础知识——新手可以从这里开始学习,有经验的人也可以借此巩固知识;第二天则涉及到应用程序之类的稍稍复杂的主题。项目中也提供了不少的 demo,如果在这之前有过一些关于 web 开发的经验的话,能够从中学到更多的东西。
今日推荐英文原文:《A Beginner’s Guide to Machine Learning》作者:Shaurya Bhandari
原文链接:https://blog.usejournal.com/a-beginners-guide-to-machine-learning-5f20f884d574
推荐理由:用简单的方法介绍机器学习,适合那些需要重温机器学习或者是想要介绍和学习机器学习的人
A Beginner’s Guide to Machine Learning
(Easy, plain English explanations accompanied by the math, code, and real-life problem examples)“Karma of humans is Artificial Intelligence”
Who should read this?
- Technical people who wish to revisit machine learning quickly.
- Non-technical people who want an introduction to machine learning but have no idea about where to start with.
- Anybody who thinks machine learning is “hard.”
Why Machine Learning?
Artificial Intelligence will shape our future more powerfully than any other innovation, this century. The rate of acceleration of AI is already astonishing. After two AI winters over the past four decades, rapidly growing volumes and varieties of available data, computational processing that is cheaper and more powerful, and affordable data storage, the game is now changing.In this post, you will explore core machine learning concepts and algorithms behind all the technology that powers much of our day-to-day lives. By the end of this, you would be able to describe how it functions at the conceptual level and be equipped with the tools to start building similar models and applications yourself.
Prerequisites to start with machine learning?
To understand the concepts presented, it is recommended that one meets the following prerequisites:- In-depth knowledge of intro-level algebra: One should be comfortable with variables and coefficients, linear equations, calculus and understanding of graphs.
- Proficiency in programming basics, and some experience coding in Python: No prior experience with machine learning is required, but one should feel comfortable reading and writing Python code that contains basic programming constructs, such as function definitions/invocations, lists, dictionaries, loops, and conditional expressions.
- Basic knowledge of the following Python libraries:
- NumPy
- Pandas
- SciKit-Learn
- SciPy
- Matplotlib (and/or Seaborn)
The Semantic Tree:
Artificial intelligence is the study of agents that perceive the world around them, form plans, and make decisions to achieve their goals.Machine learning is a subfield of artificial intelligence. Its goal is to enable computers to learn on their own. A machine’s learning algorithm enables it to identify patterns in observed data, build models that explain the world, and predict things without having explicit pre-programmed rules and models.

The semantic tree
What is Machine Learning?
Arthur Samuel described machine learning as: “The field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition which now holds little meaning.Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
In simpler terms, Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code which is specific to a problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
You can think of machine learning algorithms as falling into one of the three categories ——— Supervised Learning and Unsupervised Learning and Reinforcement Learning.
- Supervised Learning: A supervised learning algorithm takes labeled data and creates a model that can make predictions given new data. This can be either a classification problem or a regression problem.
- Unsupervised Learning: Unsupervised learning is when we are dealing with data that has not been labeled or categorized. The goal is to find patterns and create structure in data in order to derive meaning. Two forms of unsupervised learning are clustering and dimensionality reduction.
- Reinforcement Learning: Reinforcement learning uses a reward system and trial-and-error in order to maximize the long-term reward.
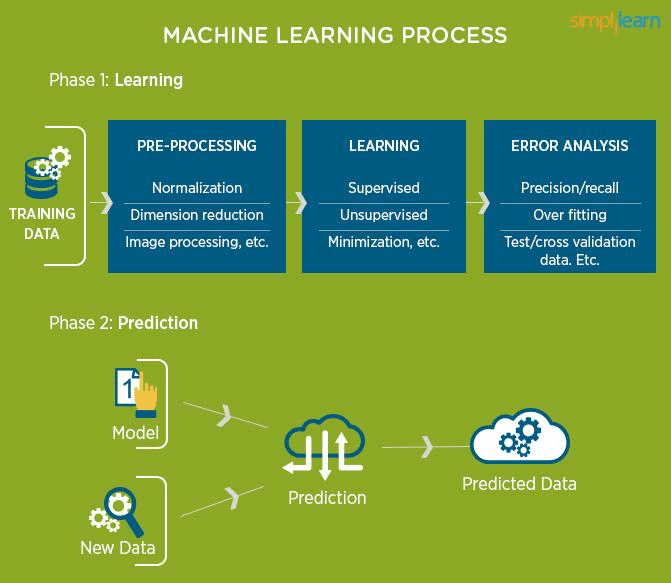
The workflow in machine learning
Roadmap to begin with Machine Learning:
- The place to start is to learn (and/or) revise linear algebra. MIT has provided an amazing open course on linear algebra. This should introduce you to all the core concepts of linear algebra, and you should pay particular attention to vectors, matrix multiplication, determinants, and Eigenvector decomposition — all of which play pretty heavily as the cogs that make machine learning algorithms work.
- After that, calculus should be your next focus. Here you should be most interested in learning and understanding the meaning of derivatives, and how we can use them for optimization. You should make sure to get through all topics in Single Variable Calculus and (at least) sections 1 and 2 of Multivariable Calculus.
- Get thorough with Python libraries used in machine learning, mainly Numpy, Pandas, Matplotlib and SKLearn. Machine learning without all these, what I like to call ‘Tools’ would be quite tough.
- Get coding! It’s always advised to implement all algorithms from scratch in Python before using the premade models in SciKit - Learn, as it gives you a better and in-depth knowledge of how it works. I personally did the algorithms in the following order of growing complexity, but you may start off anywhere :
- Linear Regression
- Logistic Regression
- Naive Bayes Classifier
- K - Nearest Neighbors (KNN)
- K - Means
- Support Vector Machine (SVM)
- Decision Trees
- Random Forests
- Gradient Boosting
Algorithm Implementation Roadmap:
- Get data to work on. There are millions of data sets available on the internet, catering to even the weirdest of your needs. Kaggle and UCI are great resources to look out for data sets. One can also generate her/his own data as I have done in a few of my algorithm implementations.
- Choosing an algorithm(s). Once you have the data in a good place to work with it, you can start trying different algorithms. The image below is a rough guide. (From SKLearn’s documentation)
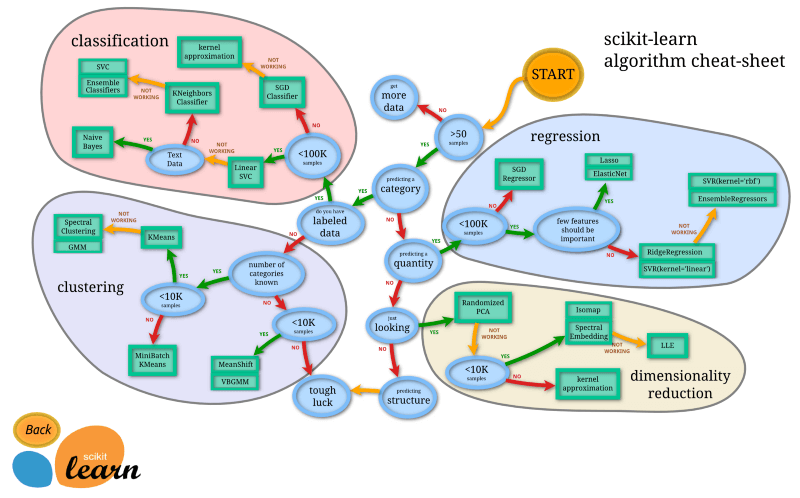
At this stage, I highly recommend you to go through the short theory of each algorithm that I have uploaded on my Github with each implementation. You can also go through Joel Grus’s Github, where he has documented all the implementations from his book, “Data Science from Scratch”.
- Visualise the data! Python has various libraries such as Matplotlib and Seaborn that help us plot the data and then the final result, to help us get a better intuition of your data and what you will be doing. (and of course, makes the model look fancy!)
Tune the algorithm. All the models that we implement, have tons of buttons and knobs to play around with, better known as hyper-parameters. The learning rate, the k value, etc. all can be changed to get the best possible model.
Evaluate the model. The Python library, SKLearn provides a lot of tools to evaluate your model and check for metrics such as accuracy, f1 score, precision etc.
Side notes:
- Once you get familiar with a few algorithms and concepts, jump into one short term project(s) that isn’t super complex (to begin with).
- Don’t be afraid to fail. The majority of your time, in the beginning, will be spent trying to figure out the math, or how and why an error popped up. But, tenacity is key.
- These small models are a sandbox for learning a lot by failing — so make use of it and give everything a try, even if it doesn’t really make sense to someone else. If it makes sense to you, it might turn out to be the best fit model.
- Helpful resources to get started with Python:
https://www.python-course.eu/index.php
Learning Python the hard way (book)
- Helpful resources for the math used in machine learning:
https://ocw.mit.edu/courses/mathematics/18-01-single-variable-calculus-fall-2006/video-lectures
https://ocw.mit.edu/courses/mathematics/18-02sc-multivariable-calculus-fall-2010/index.htm
Math4ML (book)
Elements of Statistical Learning (book)
- The best way to go around Python libraries is either through Datacamp courses or directly through their official documentation.
- If you really wish to dive deep into machine learning then I would recommend you to start with any one of the following :
CS-229 course by Stanford University (free, relatively tougher, complex math)
All that I discussed above can be found on my Github, in the Machine-Learning repository. All the algorithms are systematically arranged, with both implementations from scratch and using SciKit-Learn. The data sets used are provided with each and also there is a short theory report about how the algorithms work, along with a real-life example.
I personally decided to get thorough with machine learning first before starting off with Deep Learning and I advise you to do the same, it is not necessary to go with the herd, just because Deep Learning is the new, hot topic in the industry.
Feel free to point out any mistakes you find, constructive criticism does no harm.
下载开源日报APP:https://openingsource.org/2579/
加入我们:https://openingsource.org/about/join/
关注我们:https://openingsource.org/about/love/
