今日推薦開源項目:《動可生靜 awesome-dynamic-analysis》
今日推薦英文原文:《Will AI reduce the need for technical writers?》

今日推薦開源項目:《動可生靜 awesome-dynamic-analysis》傳送門:GitHub鏈接
推薦理由:動可生靜,此乃常理也。這個項目就是一個對軟體進行的動態分析——很實際的去執行它們。相比之下隔壁的靜態分析列表就受歡迎的多……這邊的列表裡有不少都是關於內存錯誤的,如果有需要的話也可以用來檢查自己的代碼。同樣的是,如果能夠依靠自己的力量就能避免寫出導致內存錯誤的代碼就再好不過了。
今日推薦英文原文:《Will AI reduce the need for technical writers?》作者:James Scott
原文鏈接:https://medium.com/@scottydocs/will-ai-reduce-the-need-for-technical-writers-79ccfb53429f
推薦理由:AI 的出現會給作家帶來什麼樣的影響?實際上,AI 肯定不能完全取代作家
Will AI reduce the need for technical writers?
The late Stephen Hawking famously said that artificial intelligence would be 「either the best, or the worst thing, ever to happen to humanity.」 As a technical writer documenting AI technology, I』d like to believe it would be the former and it』s fair to say there have already seen positive signs about how AI might shape and assist with documentation in the future.
A number of tech companies have already dipped their toes into the water, with some developing AI-assisted, predictive content generation and others harnessing machine learning to predict the help content the end-user is looking for.
AI-assisted content writing
Google introduced its natural language processing development, Smart Compose, to help Gmail users write emails in May 2018. They combined a bag-of-words (BoW) model with a recurring-neural-network (RNN) model to predict the next word or word sequence the user will type depending on the prefix word sequence previously typed.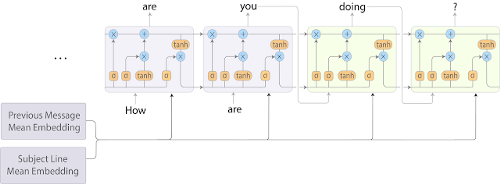
The Google Smart Compose RNN-LM model architecture.
Smart Compose was trained with a corpus of billions of words, phrases and sentences, and Google carried out vigorous testing to make sure the model only memorised the common phrases used by its many users. The Google team admits it has more work to do and is working on incorporating their own personal language models that will more accurately emulate each individual』s style of writing.
Arguably one of their biggest challenges they face is reducing the human-like biases and subsequent unwanted and prejudicial word associations that AI inherits from a corpus of written text. Google cited research by Caliskan et al which found that machine learning models absorbed stereotyped biases. At the most basic level, the models associated floral words with something pleasant and insect words as something unpleasant. More worryingly, they also found the machine-learning models adopted racial and gender biases.

Caliskan et al found AI models absorbed gender and racial biases from a large body of text.
The researchers found that a group of European American names were more readily associated with pleasant than unpleasant terms when compared to a batch of African American names. They also found inherited biases included associating female names and words with family and the arts while male names were associated with career and science words.
Yonghui Wu, the principal engineer from the Google Brain team, said: 「…these associations are deeply entangled in natural language data, which presents a considerable challenge to building any language model. We are actively researching ways to continue to reduce potential biases in our training procedures.」
AI-assisted spelling and grammar
With 6.9 million daily users, one of the most common tools people are using to assist with the accuracy of their spelling and grammar is Grammarly. The company are experimenting with AI techniques including machine learning and natural language processing so the software can essentially understand human language and come up with writing enhancements.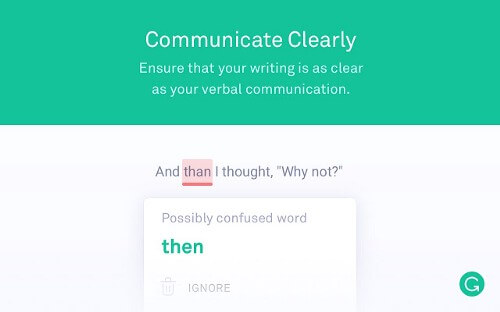
Grammarly has been training different algorithms to measure the coherence of naturally-written text using a corpus of text compiled from public sources including Yahoo Answers, Yelp Reviews and government emails. The models they have experimented with include:
- Entity-based model — Tracks specific entities in the text. For example, if it finds the word 「computer」 in multiple sentences it assumes they are related to each other.
- Lexical coherence graph — Treats sentences as nodes in a graph with connections (「edges」) for sentences that contain pairs of similar words. For example, it connects sentences containing 「macbook」 and 「chromebook」 because they are both probably about laptop computers.
- Deep learning model — Neural networks that capture the meaning of each sentence and are able to combine these sentence representations to learn the overall meaning of a document.
AI-assisted help content
Some companies have also started to look at ways that AI can help with predicting and directing readers to the exact content they are looking for. London-based smart bank Monzo launched a machine-learning powered help system for their mobile app in August 2017.
Their data science team trained a model of recurring-neural-networks (RNNs) with commonly asked customer support questions to make predictions based on a sequence of actions or 「event time series」. For example:
User logs in → goes to Payments → goes to Scheduled payments → goes to Help.
At this point, the help system provides suggestions relating to payments and as the user starts typing, returns common questions and answers relating to scheduled payments. Their initial tests showed they were able to reach 53% accuracy when determining the top three potential categories that users were looking for out of 50 possible support categories. You can read more about their help search algorithm here.
What does the future hold?
I think we will see more content composition tools like Smart Compose emerge but it will take a lot of time and work before they can be trained to effectively assist with the complex and often unpredictable user-oriented content that technical writers are tasked with producing on a daily basis.
I』m sure some technical writers are already using Grammarly to assist with their spelling and grammar. It can be a really powerful tool to ensure your text is not only accurate but in the future it will be able to measure whether your writing is actually coherent and readable. I』ve dabbled with Grammarly but found it either wasn』t compatible with certain tools or prevented some of my applications from working so it became a bit of hindrance rather than an assistant for me personally. No doubt these are kinks they will iron out at some point down the line.
I do see the benefits of AI-assisted help like Monzo have created so it would be awesome to see some more development in this area. It could potentially be something that saves customer support and documentation teams a lot of time in terms of predicting and directing end-users to answers before they』ve even asked a question.
So are we there yet? Not quite… but I think some very promising foundations have been laid. While some technical writers might be concerned, I think it will be a very long time before AI is advanced enough to supplant our role in the development teams. So don』t be afraid of AI, for the time being these tools are only going to make our lives easier!
下載開源日報APP:https://openingsource.org/2579/
加入我們:https://openingsource.org/about/join/
關注我們:https://openingsource.org/about/love/
