每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

今日推荐开源项目:《基于 Java 的社区平台 symphony》传送门:GitHub链接
推荐理由:这个开源的社区平台几乎已经完成了绝大多数作为一个普通论坛需要的功能,而且还提供了诸如连接个人博客内容和论坛帖子内容,编辑时自动处理剪贴板这样的方便功能。不过相比于开源版,推荐企业网站和盈利网站使用的闭源商业版则增添了更多方便的特性,不过在小编看来……购买闭源版那 ¥20000 价格还是不算少的。
顺带一提,这个英文单词的意思可不是同情心,同情心是 Sympathy,交响乐才是 Symphony。
今日推荐英文原文:《That time I coded 90-hours in one week.》作者:Bob Jordan
原文链接:https://medium.com/@bmjjr/that-time-i-coded-90-hours-in-one-week-a28732cac754
推荐理由:当作者终于获得了安详美好的环境来专心写代码时他都干了些什么
That time I coded 90-hours in one week.
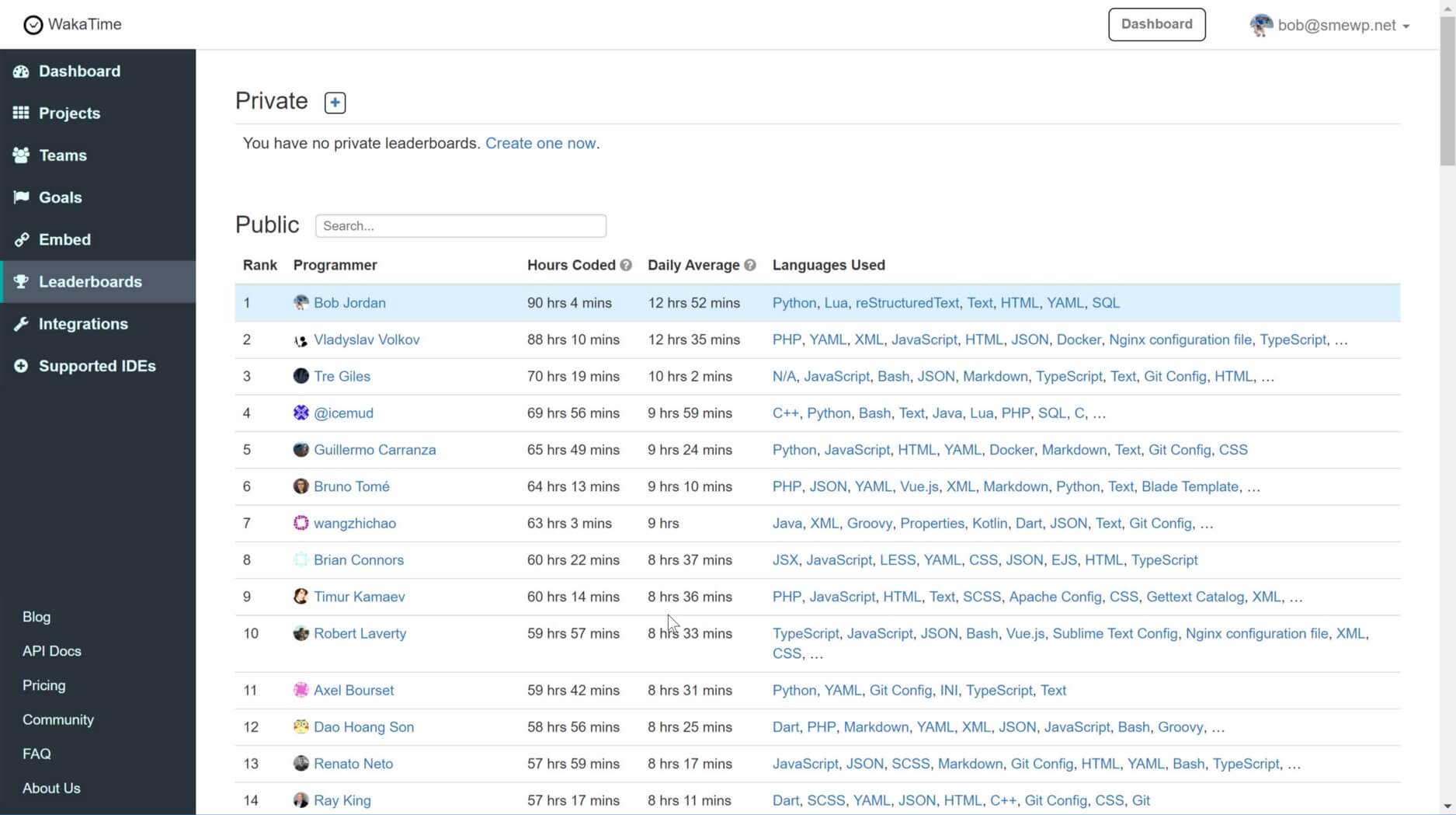
This past month in October, for various reasons, I had more time to code than I’ve probably ever had.
One week, I was able to focus on coding pretty much every waking hour. That week, I hit the #1 spot on the Wakatime coding hours leaderboard, with over 90-hours of programming time recorded.
How and why did this happen? Let me back up a bit.
My family and I live in Shenzhen, China, which is right next to Hong Kong. The first week of October is a major national holiday here.
Most companies shut down for the week, and people will travel back to their hometowns for holiday break. So, my wife, who is from China, decided to take our two kids back to her hometown, to visit my in-laws.
The in-laws live in a fairly remote place, in the far North, along the border with Russia and North Korea. It’s a 14-hour trip one-way. So, my wife planned to stay the entire month. Meanwhile, I stayed behind in Shenzhen, to work.
Now, it is a great trip, up North to see the in-laws. I get to do things like, throw rocks across a river at North Korea. And inevitably, each trip, my in-laws speak at length about how much fatter I became since my last visit.
Then, they give me acupuncture and make tasty Chinese medicines for me to drink three times per day. Yes, I missed some good times at the in-law’s house. Luckily, I’m on a diet, and I’ll see them again soon, in February.

But, let’s face it. Otherwise, it was glorious. I love to code. But, it’s hard to get that focused zone time, in your spare time, with the kids crawling on you.
At this point, I’ve been using Wakatime to track my coding hours for about three years. In all that time, I never tried to be #1 for hours coded. I’m just trying to ship some useful software for my business.
But, when I looked up after hitting several +12 hour days of coding this month, and found myself in the top 10, with the wife and kids out-of-town, well OK, game on. But, it was challenging and almost didn’t happen.
One programmer by the name of Vladyslav Volkov came on strong with his PHP fu, day after bloody day. I’ve seen days where like 70-hours over the trailing week, would take the top spot. Nope, not this week. Hell, I felt like I was in Rocky IV. I had to respond with several all-day drives, to finally take the #1 spot from Vladyslav, and ultimately maintain it for an entire day.
Hard to find that kind of competitive drive when you are coding alone and not tracking your time!
Now, time for observations and takeaways. I want to review, how does my work in October, translate into programming productivity and code quality?
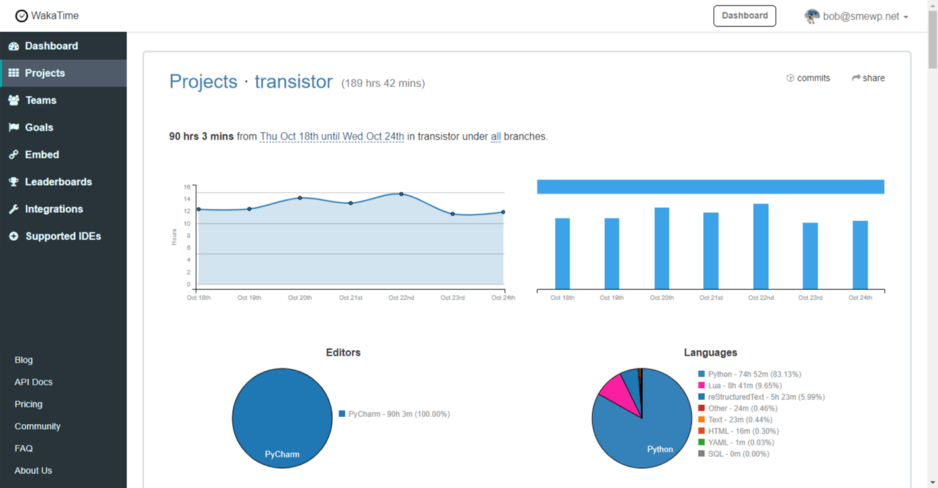
I know that some of you hackers may immediately think, “if he spent 90 hours programming in a week, it probably means, his skills are not very good.”
Well, I’m the management. Not strictly a professional programmer. I need to do a lot of other work through the week, besides programming. So, there may be some truth to that.
Programming with python has been a serious focus of my spare time over the past seven years. Before that, my skills were basically wrapped up in being a standard MBA excel jockey, with a few Access databases thrown in for depth. Which, by the way, Access can be handy. No slight from me.
With that, practice makes perfect. One Wakatime feature I like is that it allows setting a running goal for coding hours. For several years now, I’ve had a running stretch goal to hit 30 hours of coding each week.
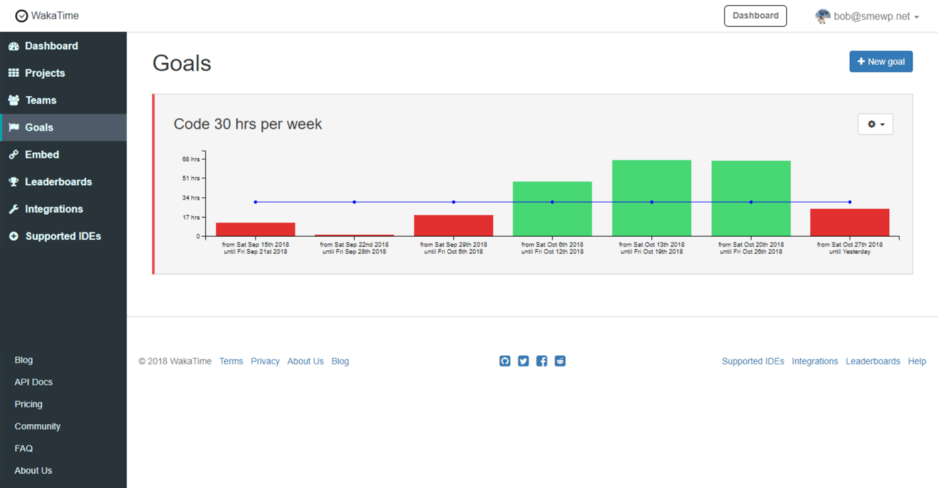
Hitting that 30-hour mark on top of everything else I deal with at work and with family is difficult. When I do achieve it, I’ve either had a rare week where everything went exceptionally smooth or else, I’ve gone out of my way to make it happen.
But now, after several years of work and practice, I’m finally at the point where I can keep my fingers hitting the keyboard, whenever I have time to code. For me, that didn’t come quick or easy.
Further, it can be a shock, after working a 12-hour day, to only end up credited for a fraction of that time. In my case, this was generally due to, #1) reading external docs, #2) googling, and #3) searching stack overflow.
All those things are great, to a point. But, they are easy to overuse, and can ultimately become a hindrance toward making real skill improvement.
With that, a key behavior tracking my coding time helped me change is, now I read a lot more source code, as the first source. And, my work is better for it.
So what am I working on? Well, from a top level. The current end-to-end experience of designing and building custom manufactured products really sucks. I’m building BOM Quote Manufacturing with a vision to make it better.
The strategy I chose in starting BOM Quote MFG seven years ago, out of necessity to earn a living while bootstrapping, is what I call, “Factory First.”
By that, I mean quite literally, first, we built a fully licensed export CM factory in Shenzhen, China. We help customers by building and shipping their custom designed retail packaged products.
Doing all the offline stuff to get our private factory setup in China, took several years of work with a hefty dose of patience. Now, we are following up with custom software, to help us improve our service, efficiencies, and scale.
With that, nearly all my 30-hours per week coding goal over these last three years went toward building our core bomquote.com web app. It aims to wrap a solid layer of communication and processes, around our interaction with both customers and suppliers.
One of the problems we repeatedly face boils down to gathering and assimilating data which is available on the internet.
For example, data about pricing and stock status for electronic components, as listed on many websites which sell such things.
Fact is, much of the data that we need to move quotes forward, especially early in the product development process, is available on the internet. We need to automate that web data gathering.
So, I present Transistor, a flexible web scraping and data persistence framework. Transistor will serve as the nucleus of our own web data collection efforts, at BOM Quote Manufacturing.
Transistor supports using scrapinghub’s Splash “javascript rendering service” as a headless browser. It also supports their crawlera “smart proxy” service. Transistor uses well-known libraries like python-requests, beautifulsoup4, mechanicalsoup, and gevent. Scrapy is not required.
Frankly, at this point, you should probably just use Scrapy, unless you suspect you have some valid reasons for not using it as I did. But, further detailing Transistor and it’s use, is better left to the README and future articles.
Transistor started as a utility module inside our core bomquote.com web app. I worked on it about 32 hours and had written the first 2000 lines of code before I decided to break it out into a dedicated repository.

That first 32 hours and 2,000 lines of code, is the part in green in the chart above. And, below is how my time looks in Wakatime for the for Transistor repository, from the initial commit with that first 2,000 LOC on October 7th:
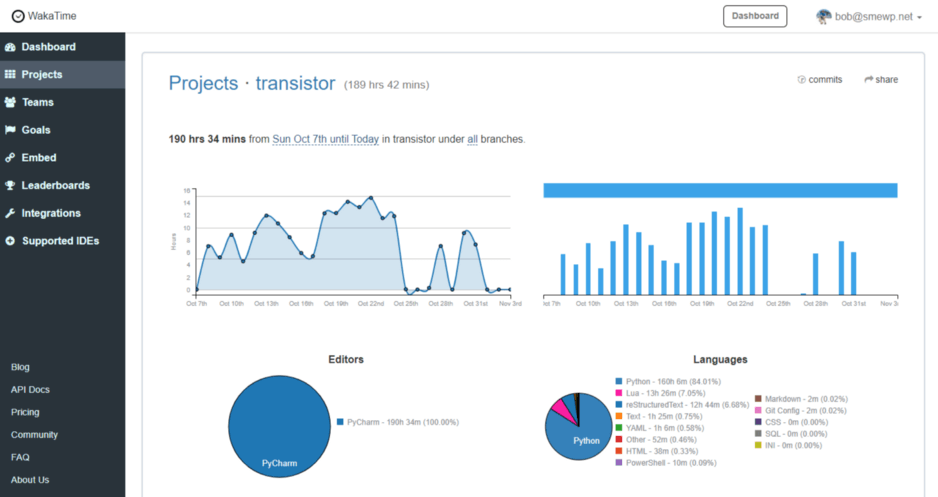
In summary, I logged about 220 total hours on Transistor in October. Factoring in about four days off from coding, that’s a little over 8-hours per day in daily average coding hours, for the days I worked.
In moving beyond hours tracked, Wakatime runs out of legs. I use other apps for insight, including codecov.io and codeclimate.com. Those two overlap a bit, in that Code Climate offers some feedback on test coverage, if you use it. While, I’ve always preferred to continue using codecov.io for test coverage, due to it’s UI.
But hands down, Code Climate is the best service I use to provide feedback on my code, other than test coverage. And, here is what Transistor looked like at the end of October, on the overview page, in Code Climate:
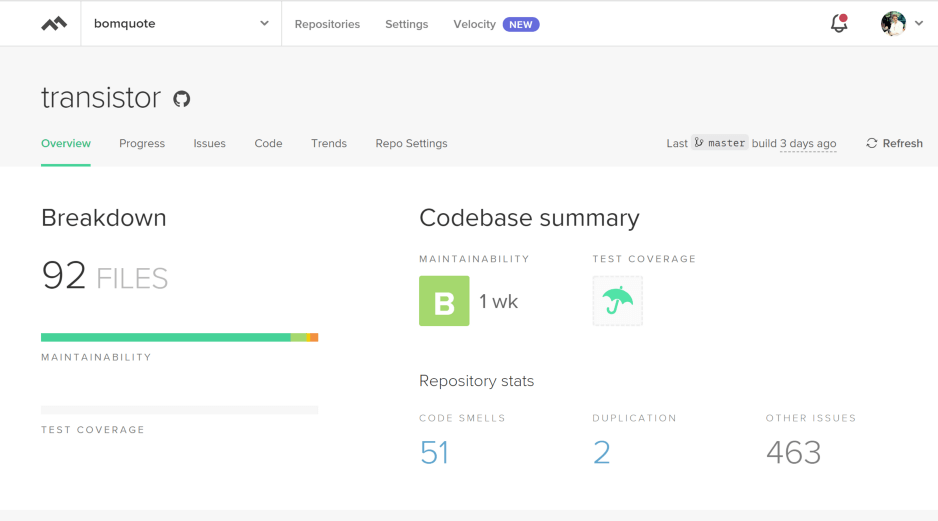
Clicking on the “Trends” tab will bring up a “Maintainability” page with a few different sections. The view defaults to the first section, “Technical Debt,” shown below:
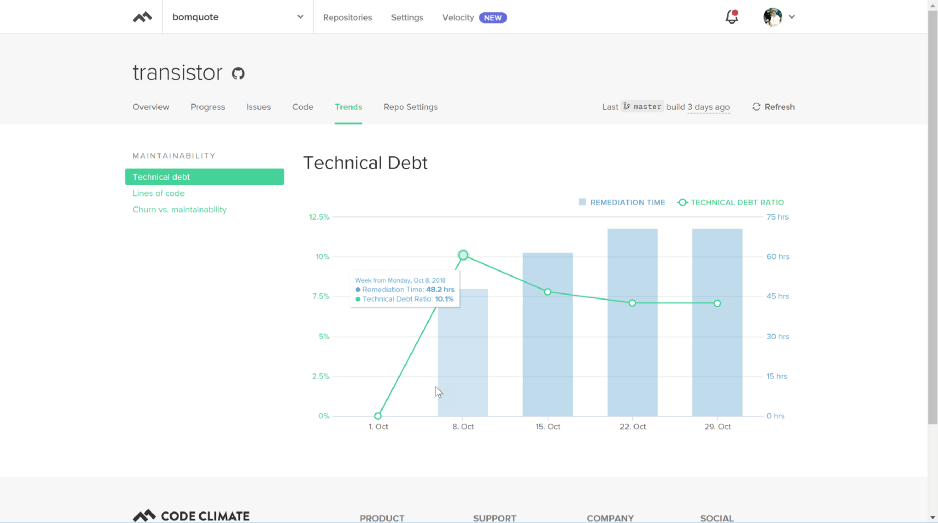
The technical debt section reports, I started with about 50 hours technical debt on my first commit, in that first 2000 lines of code. But the first 2000 lines of code only took me about 32 hours. So, I coded 32 hours to create 50 hours of technical debt? Seems a bit off.
Over the following two weeks, total debt hours increased, while the debt to lines-of-code ratio decreased, as I committed an additional 2,000 lines of code. While only adding 20 hours more technical debt over that time frame.
So, what is technical debt? Basically, it is a measure of the estimated time required to resolve items that Code Climate surmises I should fix in my code.
For example, functions and class methods with high “cognitive complexity.” In my case, there were two “D” graded files for my initial pass at low-level website scrape logic, with about 300 lines of code in each file.
I knew that code was nasty when I wrote it, but thanks Code Climate, for confirming it. And, most of the 463 other issues are PEP-8 infractions for line code length. Should be 79 chars while I set mine at 88 chars. Sorry, not sorry.
Takeaway? I love the code grades and smell highlights. But, it also seems to me, they’ve overstated the technical debt workload. It should take me like one day, to clean up a majority of the noted technical debt issues. Definitely, not seventy hours of work.
Further, it is off by such an amount that, I’d hate to expose my team to those time estimates as anchor points. The code climate algorithm could use some management tuning. Shouldn’t blindly accept that number from the team.
Next, Code Climate has a lines-of-code chart. It shows, my first repository commit was on October 8th. And, it shows that in October, I committed about 4000 lines of code to Transistor.
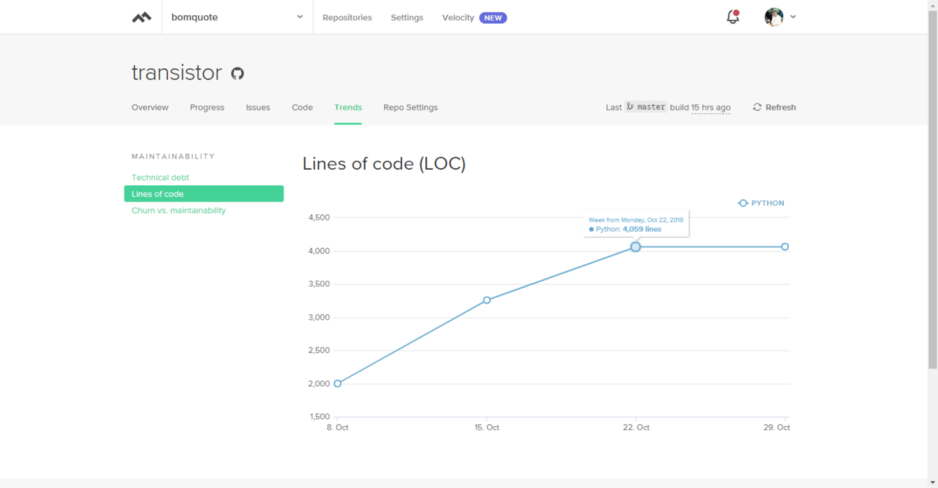
In my first week developing Transistor, I had an open canvas. So, it was not super challenging to write 2000 lines of python code from scratch. But after that, it became more difficult to churn out lines.
This chart shows, I only wrote 800–900 lines, the week I worked 90 hours, Oct 17-Oct 24th. Looking back, by then, I was more constrained in my canvas and spent much of the week optimizing Lua scripts to reduce crawl time. The result was, my LOC per work-hour, dropped quickly.
Takeaway? Lines of code helps tell a story, but it isn’t the full story. Productivity gauged on LOC must be done in full light of the situation.
Now, if you’ve made it this far, some of you TDD adherents may be saying, “but the test coverage! How are the tests!”
Well, I love tests. And, we will use Transistor in our bomquote.com web app, which currently has +1300 tests. I did write 24 tests to help ensure I didn’t break things while abstracting into a more general framework.
But, working solo on a new framework with a churning API while in create mode, I’d prefer to write most tests when I’m done creating. That’s non-zone time work which I’ll fit in-between helping my kids play Minecraft.
Next, a note about ergonomics. I use the classic Microsoft Sculpt accessories, and I don’t try an all-day coding session without them. I also always use a high-quality solid aluminum trackpad which stays very cool to the touch against my skin. This soothes my wrist when I use the mouse.
Lastly, if you don’t use a programming time tracker like Wakatime, I can recommend it. I’d probably be about half as productive, without tracking my time. If you are serious about getting coding done, track your time.
Happy coding!
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg
