每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

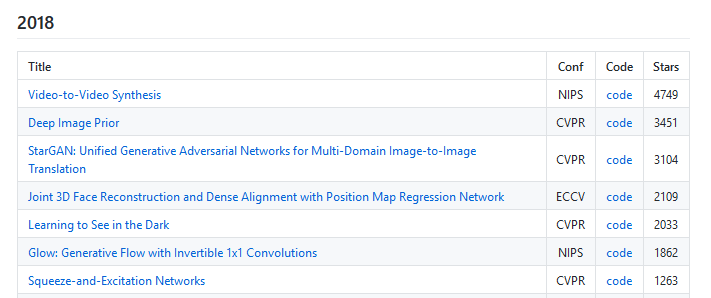
今日推荐开源项目:《相信我你不可能把它们都看一遍 pwc》传送门:GitHub链接
推荐理由:Paper with code,看项目名就知道这个项目里记录了相当数量的 Paper,每一个 Paper 的后面都附带上了代码(大部分以 GitHub 上的项目形式提供)。顺带一提,你可以在上面看到的不仅是最近的项目和 Paper,到目前为止你已经可以看到2014年的资料了,兴许等项目继续更新下去,我们就能看到十年前的 Paper 大部分关注点都放在了哪里。
今日推荐英文原文:《Write Better Python Functions》作者:Jeff Knupp
原文链接:https://hackernoon.com/write-better-python-functions-c3a9a36382a6
推荐理由:什么是好的 Python 函数以及如何写出好的函数,实际上文中提到的好的函数的要点不仅仅适用于 Python,你会发现在任何时候它们中的大部分都能够派上用场。
Write Better Python Functions
In Python, like most modern programming languages, the function is a primary method of abstraction and encapsulation. You’ve probably written hundreds of functions in your time as a developer. But not all functions are created equal. And writing “bad” functions directly affects the readability and maintainability of your code. So what, then, is a “bad” function and, more importantly, what makes a “good” function?
A Quick Refresher
Math is lousy with functions, though we might not remember them, so let’s think back to everyone’s favorite topic: calculus. You may remember seeing formulas like the following f(x) = 2x + 3. This is a function, called f, that takes an argument x, and "returns" two times x + 3. While it may not look like the functions we're used to in Python, this is directly analogous to the following code:
Functions have long existed in math, but have far more power in computer science. With this power, though, comes various pitfalls. Let’s now discuss what makes a “good” function and warning signs of functions that may need some refactoring.
Keys To A Good Function
What differentiates a “good” Python function from a crappy one? You’d be surprised at how many definitions of “good” one can use. For our purposes, I’ll consider a Python function “good” if it can tick off most of the items on this checklist (some are not always possible):
- Is sensibly named
- Has a single responsibility
- Includes a docstring
- Returns a value
- Is not longer than 50 lines
- Is idempotent and, if possible, pure
For many of you, this list may seem overly draconian. I promise you, though, if your functions follow these rules, your code will be so beautiful it will make unicorns weep. Below, I’ll devote a section to each of the items, then wrap things up with how they work in harmony to create “good” functions.
Naming
There’s a favorite saying of mine on the subject, often misatributed to Donald Knuth, but which actually came from Phil Karlton:
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
As silly as it sounds, naming things well is difficult. Here’s an example of a “bad” function name:
Now, I’ve seen bad names literally everywhere, but this example comes from Data Science (really, Machine Learning), where its practitioners typically write code in Jupyter notebooks and later try to turn those various cells into a comprehensible program.
The first issue with the name of this function is its use of acronyms/abbreviations. Prefer full English words to abbreviations and non-universally known acronyms. The only reason one might abbreviate words is to save typing, but every modern editor has autocomplete, so you’ll only be typing that full name once. Abbreviations are an issue because they are often domain specific. In the code above, knn refers to "K-Nearest Neighbors", and df refers to "DataFrame", the ubiquitous pandas data structure. If another programmer not familiar with those acronyms is reading the code, almost nothing about the name will be comprehensible to her.
There are two other minor gripes about this function’s name: the word “get” is extraneous. For most well-named functions, it will be clear that something is being returned from the function, and its name will reflect that. The from_df bit is also unnecessary. Either the function's docstring or (if living on the edge) type annotation will describe the type of the parameter if it's not already made clear by the parameter's name.
So how might we rename this function? Simple:
def k_nearest_neighbors(dataframe):
It is now clear even to the lay person what this function calculates, and the parameter’s name (dataframe) makes it clear what type of argument should be passed to it.
Single Responsibility
Straight from “Uncle” Bob Martin, the Single Responsibility Principle applies just as much to functions as it does classes and modules (Mr. Martin’s original targets). It states that (in our case) a function should have a single responsibility. That is, it should do one thing and only one thing. One great reason is that if every function only does one thing, there is only one reason ever to change it: if the way in which it does that thing must change. It also becomes clear when a function can be deleted: if, when making changes elsewhere, it becomes clear the function’s single responsibility is no longer needed, simply remove it.
An example will help. Here’s a function that does more than one “thing”:
This function does two things: it calculates a set of statistics about a list of numbers and prints them to STDOUT. The function is in violation of the rule that there should be only one reason to change a function. There are two obvious reasons this function would need to change: new or different statistics might need to be calculated or the format of the output might need to be changed. This function is better written as two separate functions: one which performs and returns the results of the calculations and another that takes those results and prints them. One dead giveaway that a function has multiple responsibilities is the word and in the functions name.
This separation also allows for much easier testing of the function’s behavior and also allows the two parts to be separated not just into two functions in the same module, but possibly live in different modules altogether if appropriate. This, too, leads to cleaner testing and easier maintenance.
Finding a function that only does two things is actually rare. Much more often, you’ll find functions that do many, many more things. Again, for readability and testability purposes, these jack-of-all-trade functions should be broken up into smaller functions that each encapsulate a single unit of work.
Docstrings
While everyone seems to be aware of PEP-8, defining the style guide for Python, far fewer seem to be aware of PEP-257, which does the same for docstrings. Rather than simply rehash the contents of PEP-257, feel free to read it at your leisure. The main takeaways, however, are:
- Every function requires a docstring
- Use proper grammar and punctuation; write in complete sentences
- Begins with a one-sentence summary of what the function does
- Uses prescriptive rather than descriptive language
This is an easy one to tick off when writing functions. Just get in the habit of always writing docstrings, and try to write them before you write the code for the function. If you can’t write a clear docstring describing what the function will do, it’s a good indication you need to think more about why you’re writing the function in the first place.
Return Values
Functions can (and should) be thought of as little self-contained programs. They take some input in the form of parameters and return some result. Parameters are, of course, optional. Return values, however, are not optional, from a Python internals perspective. Even if you try to create a function that doesn’t return a value, you can’t. If a function would otherwise not return a value, the Python interpreter “forces it” to return None. Don't believe me? Test out the following yourself:
❯ python3 Python 3.7.0 (default, Jul 23 2018, 20:22:55) [Clang 9.1.0 (clang-902.0.39.2)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> def add(a, b): ... print(a + b) ... >>> b = add(1, 2) 3 >>> b >>> b is None True
You’ll see that the value of b really is None. So, even if you write a function with no return statement, it's still going to return something. And it should return something. After all, it's a little program, right. How useful are programs that produce no output, including whether or not they executed correctly? But most importantly, how would you test such a program?
I’ll even go so far as to make the following statement: every function should return a useful value, even if only for testability purposes. Code that you write should be tested (that’s not up for debate). Just think of how gnarly testing the add function above would be (hint: you'd have to redirect I/O and things go south from there quickly). Also, returning a value allows for method chaining, a concept that allows us to write code like this:
with open('foo.txt', 'r') as input_file:
for line in input_file:
if line.strip().lower().endswith('cat'):
# ... do something useful with these lines
The line if line.strip().lower().endswith('cat'): works because each of the string methods (strip(), lower(), endswith()) return a string as the result of calling the function.
Here are some common reasons people give when asked why a given function they wrote doesn’t return a value:
“All it does is [some I/O related thing like saving a value to a database]. I can’t return anything useful.”
I disagree. The function can return True if the operation completed successfully.
“We modify one of the parameters in place, using it like a reference parameter.”””
Two points, here. First, do your best to avoid this practice. For others, providing something as an argument to your function only to find that it has been changed can be surprising in the best case and downright dangerous in the worst. Instead, much like the string methods, prefer returning a new instance of the parameter with the changes applied to it. Even when this isn’t feasible because making a copy of some parameter is prohibitively expensive, you can still fall back to the old “Return True if the operation completed successfully" suggestion.
“I need to return multiple values. There is no single value I could return that would make sense.”
This is a bit of a straw-man argument, but I have heard it. The answer, of course, is to do exactly what the author wanted to do but didn’t know how to do: use a tuple to return more than one value.
And perhaps the most compelling argument for always returning a useful value is that callers are always free to ignore them. In short, returning a value from a function is almost certainly a good idea and very unlikely to break anything, even in existing code bases.
Function Length
I’ve said a number of times that I’m pretty dumb. I can only hold about 3 things in my head at once. If you make me read a 200 line function and ask what it does, my eyes are likely to glaze over after about 10 seconds. The length of a function directly affects readability and, thus, maintainability. So keep your functions short. 50 lines is a totally arbitrary number that seemed reasonable to me. Most functions you write will (hopefully) be quite a bit shorter.
If a function is following the Single Responsibility Principle, it is likely to be quite short. If it is pure or idempotent (discussed below), it is also likely to be short. These ideas all work in concert together to produce good, clean code.
So what do you do if a function is too long? REFACTOR! Refactoring is something you probably do all the time, even if the term isn’t familiar to you. It simply means changing a program’s structure without changing its behavior. So extracting a few lines of code from a long function and turning them into a function of their own is a type of refactoring. It’s also happens to be the fastest and most common way to shorten a long function in a productive way. And since you’re giving all those new functions appropriate names, the resulting code reads much more easily. I could write a whole book on refactoring (in fact it’s been done many times) and won’t go into specifics here. Just know that if you have a function that’s too long, the way to fix it is through refactoring.
Idempotency and Functional Purity
The title of this subsection may sound a bit intimidating, but the concepts are simple. An idempotent function always returns the same value given the same set of arguments, regardless of how many times it is called. The result does not depend on non-local variables, the mutability of arguments, or data from any I/O streams. The following add_three(number) function is idempotent:
def add_three(number):
"""Return *number* + 3."""
return number + 3
No matter how many times one calls add_three(7), the answer will always be 10. Here's a different take on the function that is not idempotent:
def add_three():
"""Return 3 + the number entered by the user."""
number = int(input('Enter a number: '))
return number + 3
This admittedly contrived example is not idempotent because the return value of the function depends on I/O, namely the number entered by the user. It’s clearly not true that every call to add_three() will return the same value. If it is called twice, the user could enter 3 the first time and 7 the second, making the call to add_three() return 6 and 10, respectively.
A real-world example of idempotency is hitting the “up” button in front of an elevator. The first time it’s pushed, the elevator is “notified” that you want to go up. Because the pressing the button is idempotent, pressing it over and over again is harmless. The result is always the same.
Why is idempotency important?
Testability and maintainability. Idempotent functions are easy to test because they are guaranteed to always return the same result when called with the same arguments. Testing is simply a matter of checking that the value returned by various different calls to the function return the expected value. What’s more, these tests will be fast, an important and often overlooked issue in Unit Testing. And refactoring when dealing with idempotent functions is a breeze. No matter how you change your code outside the function, the result of calling it with the same arguments will always be the same.
What is a “pure” function?
In functional programming, a function is considered pure if it is both idempotent and has no observable side effects. Remember, a function is idempotent if it always returns the same value for a given set of arguments. Nothing external to the function can be used to compute that value. However, that doesn’t mean the function can’t affect things like non-local variables or I/O streams. For example, if the idempotent version of add_three(number) above printed the result before returning it, it is still considered idempotent because while it accessed an I/O stream, that access had no bearing on the value returned from the function. The call to print() is simply a side effect: some interaction with the rest of the program or the system itself aside from returning a value.
Let’s take our add_three(number) example one step further. We can write the following snippet of code to determine how many times add_three(number) was called:
add_three_calls = 0
def add_three(number):
"""Return *number* + 3."""
global add_three_calls
print(f'Returning {number + 3}')
add_three_calls += 1
return number + 3
def num_calls():
"""Return the number of times *add_three* was called."""
return add_three_calls
We’re now printing to the console (a side effect) and modifying a non-local variable (another side effect), but since neither of these affect the value returned by the function, it is still idempotent.
A pure function has no side effects. Not only does it not use any “outside data” to compute its value, it has no interaction with the rest of the system/program other than computing and returning said value. Thus while our new add_three(number) definition is still idempotent, it is no longer pure.
Pure functions do not have logging statements or print() calls. They do not make use of database or internet connections. They don't access or modify non-local variables. And they don't call any other non-pure functions.
In short, they are incapable of what Einstein called “spooky action at a distance” (in a Computer Science setting). They don’t modify the rest of the program or system in any way. In imperative programming (the kind you’re doing when you write Python code), they are the safest functions of all. They are eminently testable and maintainable and, even more so than mere idempotent functions, testing them is guaranteed to basically be as fast as executing them. And the test(s) itself is simple: there are no database connections or other external resources to mock, no setup code required, and nothing to clean up afterwards.
To be clear, idempotency and purity are aspirational, not required. That is, we’d love to only write pure or idempotent functions because of the benefits mentioned, but that isn’t always possible. The key, though, is that we naturally begin to arrange our code to isolate side effects and external dependencies. This has the effect of making every line of code we write easier to test, even if we’re not always writing pure or idempotent functions.
Summing Up
So that’s it. The secret to writing good functions is not a secret at all. It just involves following a number of established best-practices and rules-of-thumb. I hope you found this article helpful. Now go forth and tell your friends! Let’s all agree to just always write great code in all cases :). Or at least do our best not to put more “bad” code into the world. I’d be able to live with that…
Posted on Oct 11, 2018 by Jeff Knupp
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

写好一个函数,在任何时候都能够发挥很大的作用啊,最简单而言,当你看到它立刻明确地知晓它的作用,不管自己再回看或者别人来看都是很方便的,并且并不仅适用于写Python函数,写任何代码时都该简洁规范。写好代码,造福大家 😛