每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

今日推荐开源项目:《DLW Deep Learning World》传送门:GitHub链接
推荐理由:这个关于深度学习的资源库按照目标进行分类,如果你知道你想要干什么,那么这个分类会很容易让你找到所需要的文章,不过即使你暂时没有目标,这里也提供了基础向的资源来阅读,推荐给正在学习深度学习的朋友们。
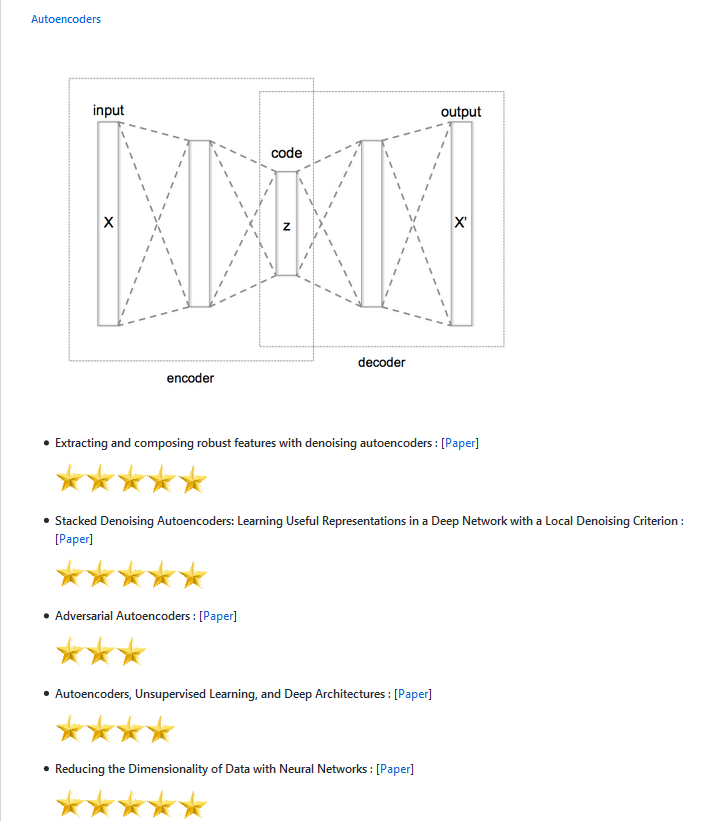
今日推荐英文原文:《Meeting the Needs of AI》作者:Journal of Beautiful Business
原文链接:https://journalofbeautifulbusiness.com/meeting-the-needs-of-ai-ccd6adcf3b1e
推荐理由:关注 AI 的需求,兴许能够让 AI 更正确的发展
Meeting the Needs of AI
It is quite challenging to talk about AI without sounding like a buzzword-spewing technocrat these days. Amidst all the hemming and hawing that companies do to convince themselves that they’re still relevant (wink, wink), we forget that AI has needs too — and soon enough feelings. Let’s not forget that, since how AI learns is a direct reflection of how we treat it. But that aside, let’s look at why taking a holistic, scientifically rigorous approach to data that also accounts for human irrationalities is needed before AI can grow up.
In order to dig into what AI needs, we first need to define what we mean by AI. What businesses call AI often refers to narrow (or weak) AI: playing chess, speech and image recognition, self-driving cars, computer vision, as well as natural language processing and any other tasks that leverage machine or deep learning. When your grandma hears something about AI on the news and thinks that what you’re talking about is general artificial intelligence, you can tell her that a team of AI experts at Stanford issued a press release stating that despite all the amazing strides AI has made in the past years, “computers still can’t exhibit the common sense or the general intelligence of even a five-year-old.”
However, if AI gets all of its needs fulfilled, then it can move — much as humans did — from a very narrow and weak state towards a much stronger and more general intelligence, where each stage of the process requires a new set of needs. The very foundation of these needs begins with high quality data, AI’s basic building blocks of life.
Basic needs: high quality data
At the very basis of AI is data and even more important, quality data. If you don’t get this step right, all the algorithms in the world can’t help you: It will just be garbage in, garbage out. The first step is to figure out what data you actually need to accomplish what you want to achieve: what’s the minimum precision, reliability, and accuracy (validity) that you need as a baseline? What are the tools of measurement that you need to procure this data in an accurate, real-time manner? If you’re using data to optimize your user-facing product, go back to basics.
Human beings are first and foremost emotional decision makers which, according to behavioral economics, makes us seem a bit irrational. We have biases that cause us to use data to prove our own ideas even if we have a scientific education, and regularly make emotional decisions rather than rational ones. Added to that, the context in which we perceive things often changes the actual things themselves. Oh, and finally, our decisions are heavily influenced by our social groups.
The bottom line: Logging behaviors at face value is not enough. In today’s world, almost every form of narrow AI has a human dependency, and you must test and retest using a scientifically rigorous methodology. In the case of consumer facing products, according to neuropsychologists, human observation and data testing alone isn’t enough to accurately measure human beings. You need to get as many valid perspectives as possible on the individuals you’re researching. Think collection methods: sensors, instruments, logging, and a nice constant flow of real-time data with a great filtration (cleaning) system. After all, if learning is the generalization of past experiences combined with the results of new actions, it’s important that the data we ingest helps us be better (more efficient, etc.); that such data is measured and perceived correctly, ensuring any misperceptions are cleaned; and that there is a well-built pipeline to an abundant source that can provide as much real time data inflow as possible.
Test for error: If your instruments are not sensitive enough or if error rates are too high, you can not move forward. Our eagerness to start building algorithms on a poor foundation is the main reason that AI isn’t moving forward.
Keeping safe: it’s about storage.
Clean data with high validity? Check. Reliable intake and pipeline? Check. The next thing you need to consider, once you’ve got the goods, is . . . is it secret, is it safe, are people safe? Your data is highly valuable and in the wrong hands, it could be misused and taken out of context. Anyone using your data should know the risks of what they are working with and what it is for. Max Tegmark has said that “AI safety is the most important conversation of our time.” So seriously. Once you have some great reliable and accurate data,you need to understand what impact it has and whether this data can be used for good or bad.
If you’re an open source kind of person or sharing company kind of organization, great: make sure your documentation around your data, data collection methods, intended usage, and so on is clearly laid out and easily consumable. The bottom line is that before you go on a deep learning dive, you need to understand what the impacts of your intended experiments could yield. People have died because the basic needs of data were not met. The guy speaking out against AI is the same guy who owns a company that killed a guy as a result of AI. Let’s hope that his outspokenness was the result of his genuine concern for humanity and that this stage of AI was given an extra focus after that incident.
The reality is that if AI is not safe, or if it begins to act in ways that are dangerous to humans, it will get shut down just like Microsoft’s chatbot that learned how to be racist from users on Twitter. If AI isn’t safe for humans, it won’t make it to the next stage of its needs. Once the data is procured in a valid way, it needs to be stored safely in a system that can scale in an unlimited way and is highly durable. IBM outlines the five key attributes of data storage for AI.
Social needs: Who are we talking to, calling, and spawning
The social needs of AI can be thought of in the context of which systems are talking together and how. What APIs are you calling? What is the data in vs. data out? How reliable are your data, storage, and learning neighbors? If you don’t thoroughly understand who your future algorithms are about to rub elbows with, you run a risk of compromising what you have built. As Ellen Ullman, a renowned programmer, stated, “when algorithms start to create new algorithms, it gets farther and farther away from human agency.”
Many managers, investors, and the like will push you to call as much data as you can from what is available and build whatever you can as long as it works. Just remember that what is out there might not be as accurate as you’d like to believe, and just because it works does not mean it is ideal. Think of Google Flu: Google Flu failed to predict flu incidence even remotely accurately for 100 out of 108 weeks, despite the wealth of search data and behavioral data that Google collects. Just because a company might say they have flu data, doesn’t mean it’s good flu data. Even if it’s Google.
Learn and grow: giving your AI some esteem
So you’ve made it this far with your pursuits. Great! It’s time to dig into those metrics, segments, aggregates, and get this party started. Machine learning (ML) should never go from 0 to 60. You need to test your hypotheses first. Think of this phase as training, or the first steps of ML with your business or project. You also need to consider your company’s readiness. If you’re expecting to go from hiring your first machine-learning engineer to the terminator, be advised that it’s just not going to happen. Scaling AI efforts within your organization is just as important as culture change efforts: it takes time.
The first stages of ML involve human expertise alongside experimentation: Creating hypotheses based on the data and testing it by having an experimentation framework allows you to deploy incrementally and experiment. This will allow developers to tweak labels, double check data, and get a good idea of how the data works. It also helps the business to see the potential impact. This is a great place to establish baselines to measure future results against. Think logistic regressions or division based algorithms. Start simple. You need to think of cost to the business: what is the cheapest way to validate your hypotheses? I’m pretty sure you’re super excited to get to that next level, but not quite yet. Nail this stage and you’re going to be so much happier when you hit the next level.
Once you have a good understanding of your data, you can start to think about leveraging more complex algorithms, engaging in deep learning if your data set is big enough, or even adaptive learning. Always focus on the business objective at hand. AI is a tool and as Pei Wang has said, AI can be defined by structure, behavior, capability, function, and principle, and all of these different types of AI “will end up at different summits.” Understanding the summit your business is trying to reach, and optimizing your A/B testing, data, and algorithms around it, will help you achieve the business goals you’ve set and allow your AI to grow and thrive.
This is where traditional machine learning versus deep learning approaches become entirely dependent on your approach and business needs. As Sid Reddy mentions, “a key issue for machine learning algorithms is selection bias.” Meaning, someone with domain expertise is necessary for any ML process: Both the training data and algorithm selection ought to be selected by an individual with domain expertise. Domain expertise is still necessary for either a deep learning or machine learning pursuit.
AI actualization
AI actualization is a lot like human self actualization at the peak of Maslow’s hierarchy of needs. We like to think that we occupy that space in fleeting moments, but as a species we’re just not quite advanced enough yet to live there. The ultimate state of AI is, of course, a point where it could start at the base of Maslow’s hierarchy of needs and progress along with humans. This would mean that AI had achieved broad intelligence. For this to happen, think of every category of human intelligence: sound, sight, hearing, taste, touch, smell, proprioception, memory, recall, divergent thinking, and so on. Think of the parameters and data sets needed to make these up, inform them, and the biological as well as social mechanisms needed to be able to act them out in real time.
For AI to become more general its needs for real-time learning, the understanding of context with memory, the ability to plan and reason, metacognition, and so on, all must be met. As more valid environmental and psychological data sets become available, AI will have larger social sets to connect and learn from. Because AI broadly learns from we humans, and our understanding of our own mind, greater scientific understanding in the fields of neurological, behavioral, and social psychology are needed. And this brings us all the way back to the importance of AI’s lifeblood: healthy data.
In conclusion
You can understand where your company’s AI efforts currently are based on the conversations people are having. If they’re focused on safety needs, it means they probably have a pretty reliable data set. If they’re talking about social needs, it means that they’ve had multiple ethical conversations. If they’ve jumped straight to algorithms that they think they can just dump data into, make sure to ask what they’ve done so far.
The reality is that most of us aren’t having these conversations. We’re focused on plugging in whatever data we can find and expecting algorithms to just handle it. We’re jumping to conclusions. The mass reality is that most companies never moved past the whole “big data” hype era and are still figuring out how to properly understand what is good clean data and what is garbage. This is perhaps why KPMG found that CEOs don’t trust their data. Reports like this tell us that right now, beyond any other need, the majority of companies using AI are still at square one of AI’s needs: sound data. You can help the evolution of AI by turning to your organization and questioning the validity of your data and better understanding the business need behind the AI solution. In the coming years, as more and more companies began to care about the importance of data durability, integrity, and validity it will be time to create the next step for mankind in its pursuit of AI: the great discourse on AI safety.
Joe Schaeppi is the cofounder of 12traits and a 2018 House of Beautiful Business Resident.
The Journal is a production of The Business Romantic Society, hosts of the House of Beautiful Business. Sign up for the monthly newsletter at https://www.beautifulbusinessletters.com/
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg
