每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg

今日推荐开源项目:《多睡觉少操心(指 Git) gitignore》传送门:GitHub链接
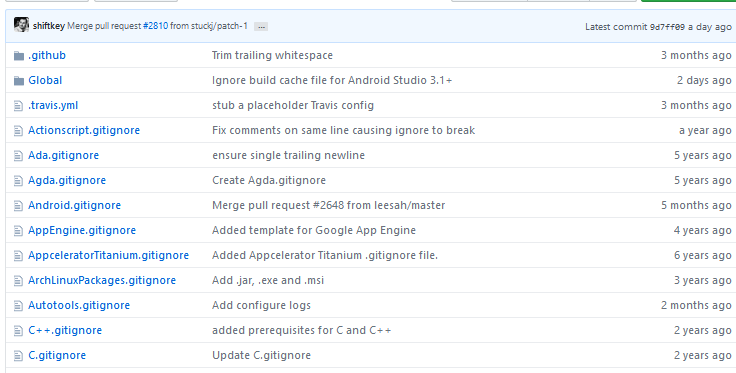
推荐理由:这个项目是一份 .gitignore 文件的合集,把需要的文件放到 git 项目的根目录下就可以避免把不需要的文件提交到版本控制中,有了这个应该能省心不少。里面直接放着的是根据特定的语言框架用的模版,而 Global 文件夹中放着的则是更泛用型的比如操作系统和编辑器这样的模版,各取所需即可。
今日推荐英文原文:《These 5 “clean code” tips will dramatically improve your productivity》作者:George Seif
推荐理由:写出高质量干净整洁代码的五个要注意的地方,可以有效的避开在队友看了你的代码之后把你打死的危机
These 5 “clean code” tips will dramatically improve your productivity
Quality code. Lots of people talk about it, but few actually do it right.
Most people who code naturally know what quality code should look or feel like. It should be very easy to read and understand quickly, there shouldn’t be any major faults, edge cases should be handled, and it should be “self documenting”. Still, many people miss the mark when trying (hopefully) to write quality code.
The cause of the mistakes are understandable in many cases. It can be challenging to predict how people will interpret your code, whether they will find it easy to read or an absolute nightmare. Not only that, once your project gets very big even you might not be able to read it!
In such a case, it’s always good to establish some principals that you can rely on. Some go-to rules that you can always reference whenever you’re designing or writing code.
The following 5 clean coding principals are the ones I code by! They’ve given me a massive productivity boost in my work and helped both myself and my colleagues be able to easily interpret and expand the code base which I’ve worked on. Hopefully they help you code faster and better too!
If it isn’t tested, it’s broken
Test, test, test. We know we should always do it, but sometimes we cut corners so we can push the project out faster. But without thorough testing, how will you 100% fully know that the code works? Yes there are very simple pieces of code, but one is always surprised when that crazy edge case comes up that you thought you didn’t need to test for!
Do yourself and everyone on your team a favour and regularly test the code you write. You’ll want to test in a coarse to fine style. Start small with unit tests to make sure every small part works on its own. Then slowly start testing the different subsystems together working your way up towards testing the whole new system end to end. Testing in this way allows you to easily track where the system breaks, since you can easily verify each individual component or the small subsystems as the source of any issues.
Choose meaningful names
This is what makes code self-documenting. When you read over your old code, you shouldn’t have to look over every little comment and run every small piece of code to figure out what it all does!
The code should roughly read like plain English. This is especially true for variable names, classes, and functions. Those three items should always have names that are self-explanatory. Rather than use a default name like “x” for example, call it “width” or “distance” or whatever the variable is supposed to represent in “read-world” terms. Coding in “real-world” terms will help make your code read in that way
Classes and functions should be small and obey the Single Responsibility Principle (SRP)
Small classes and functions make code approximately 9832741892374 times easier to read….
But seriously they really do. First off, they allow for very isolated unit testing. If the piece of code you are testing is small, it’s easy to source and debug any issues that come up in the test or during deployment. Small classes and functions also allow for better readability. Instead of having a giant block of code with many loops and variables, you can reduce that block to a function that runs several smaller functions. You can then name each of those functions according to what they do and voila, human readable code!
SRP gives you similar benefits. One responsibility means you only have to test a handful of edge cases and those cases are quite easy to debug. In addition it’s quite easy to name the function so it has real-world meaning. Since it only has one single purpose, it’ll just be named after it’s purpose, rather than trying to name a function that’s trying to accomplish so many different things.
Catch and handle exceptions, even if you don’t think you need to
Exceptions in code are usually edges case or errors that we would like to handle in our own specific way. For example, normally when an error is raised the program will stop; this definitely will not work for code we have deployed to production that is serving users! We’ll want to handle that error separately, perhaps try to see if it’s super critical or if we should just pass over it.
You should always be catching and handling exceptions specifically, even if you don’t think you need to. Better to be safe than sorry. Exception handling will give you a better sense of order and control over your code, since you know specifically what will happen if a certain exception is triggered or a piece of code fails. Having a deeper understand of your code like this makes it easier to debug and makes your code more fault tolerant.
Logs, logs, logs
Log it. What you may ask? …. Everything that’s what! There’s no such thing as too much logs!
Logs are your absolute number 1 source for debugging your code and monitoring your application when it’s in production. You should be logging every major “step” your program takes, any important calculations it makes, any errors, exceptions, or out of the ordinary results. It may also be useful to log the date and time that these events occur for easy tracking. All of this will make it easy to trace exactly which step in the pipeline the program failed.
Many common programming languages such as Python come with their own logging libraries that have some very useful functions you can play with. If your application is to run as a SaaS app, then you may want to consider off-device, centralised logging. This way if one of your servers dies you can easily recover the logs!
TL;DR
(1) If it isn’t tested, it’s broken
(2) Choose meaningful names
(3) Classes and functions should be small and obey the Single Responsibility Principle (SRP)
(4) Catch and handle exceptions, even if you don’t think you need to
(5) Logs, logs, logs
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;微博:https://weibo.com/openingsource;电报群 https://t.me/OpeningSourceOrg
