每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 https://t.me/OpeningSourceOrg
今日推荐开源项目:《整洁、模块化的浏览器文件上传组件 Uppy》
推荐理由:Uppy 是一个整洁的,模块化的,几乎可以与任何浏览器结合的文件上传组件,它快速,易用,能让你把心思放在比文件上传组件更重要的事情上。
![]()
如何使用Uppy?
Uppy应对浏览器崩溃的方法:
随着人们每天在网络上不断的进行文件传输,文件传输过程中出现意外已经司空见惯,如何在发生意外时减少使用者受到的损失已经成为了一个重要的问题。而uppy 使用了Golden Retriever 来解决这个问题。Golden Retriever 将你选定的文件保存在你的浏览器缓存之中,这样当浏览器崩溃时,uppy 也能找回所有东西继续上传。但是如果在浏览器崩溃之后没有进行恢复而是进行了某种清理缓存的操作的话……那就没办法了。
Golden Retriever 通过三种方法结合起来保存数据:
- 使用本地存储来保存文件真正的数据,在浏览器启动时恢复它们,但 uppy 不能直接访问这些数据
- 使用Service Worker 来保存对文件转变为BLOB(二进制大对象,是一个可以存储二进制文件的容器)之后的引用,虽然这会在浏览器崩溃后失效
- IndexedDB 可以永久保存BLOB 文件,但是在储存文件的量上有诸多限制
所以当uppy 启动时,信息将从本地存储中恢复,从而让uppy可以知道发生了什么。对于BLOB来说,它们将从Service Worker 和 IndexedDB中恢复。当文件成功上传后,或者是使用者决定删除它们时,Golden Retriever将会把它们自动清理掉。
虽然在有些时候Golden Retriever也无法救回丢失的进度,比如一个非常大的文件在上传时被打断,或者浏览器完全彻底的崩溃。但是至少它能保存一些这个文件的关键信息,比如它的名字和预览,以便让使用者重新添加它们。
关于tus:
tus是一个可恢复用户正在上传中文件的上传协议,支持所有平台的客户端和服务器端,当使用者结束当前进行中的上传时,服务器将存储已上传的数据(如果没有发生内部错误或者存储的数据会违反某些规定的话)。当使用者准备恢复上传时,就向相应的URL发送一个请求来获得可用的空间从而继续上传数据。但是如果经过了较长的时间还是没有完成上传的话(比如一周),服务器就将删除未完成的上传文件。
关于作者:
Artur Paikin:喜欢旅行,种植蔬菜,泡coffee,编写代码,制作网页,并且致力于家庭的自动化。他用Instagram 上传照片,用Facebook,twitter 写小说。

今日推荐英文原文:《How to Choose the Right Open Source Database》作者:
原文链接:https://opensourceforu.com/2018/04/how-to-choose-the-right-open-source-database/
推荐理由:不管你做哪种类型的开发,基本上都离不开数据库,怎么挑选一个合适的开源数据库呢?不同数据库有什么异同?应该从哪些维度去衡量一个数据库软件呢?

Databases store data in an organised manner so that its retrieval becomes easy. Also, the management of data is easier when it is stored in a database. There are many factors to be considered, however, before choosing a database for a particular software application. Let’s take a look at how we can make the right choice.
Considering the number of users working with different online applications nowadays, databases are about the most important part of any software application, and can make a huge impact on its performance. It is really difficult and time consuming for a database to operate if it has a huge load of data or if it has a variety of data sets to operate upon. There are also several other factors like the security of data, as well as the cost (if there is one) associated with the database, impacting the choice of the database. A free database helps users to avoid huge costs. Hence, open source databases have been playing quite an important role in many of the widely used software applications across the globe.
Different kinds of databases available in the market
There are various types of databases being used by different users across the globe, based on their requirement. The following is a broad classification of databases.
1. Relational databases: Relational databases are the most common among all the types. In such databases, the data is actually stored in the form of different data tables. Each of the tables has a unique key field and that key is used to connect one table to the other tables. Hence, different tables are related to each other with the help of various key fields. Such databases are widely used in industries like media, telecom, etc, and this is probably the type of database one is most likely to come across.
2. Operational databases: An operational database is very important for organisations, as it supports the customer database and the inventory database. It helps companies to keep a track of inventories as well as store details of the customers who buy its products. The data stored in various operational databases can be analysed and used based on the requirements of the company.
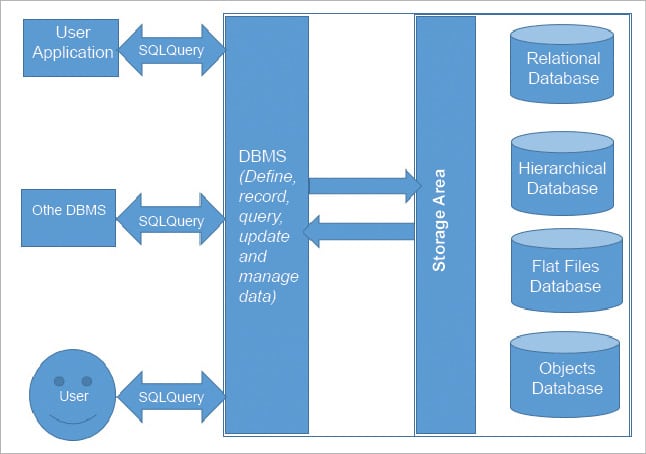
Figure 1: Interaction of a user with a DBMS
3. Database warehouses: There might be a requirement for different organisations to keep some of the relevant data for several years. Such data sets act as significant sources of information to compare and analyse the present year’s data with that of previous years, which makes it quite easy to determine key trends. All such data from previous years is maintained and stored in a large database warehouse. Since the stored data set has already gone through various kinds of editing, screening and integration, it no longer requires any editing or alteration.4. Distributed databases: Many organisations have several regional offices, manufacturing plants, branch offices and a head office. Each such work group may have its own set of databases, which collectively form the main database of the company. Such a system of databases is known as a distributed database.
5. End user databases: There is a variety of data available at the workstations of different end users of an organisation. Each workstation acts like a small database in itself, and has data in the form of spreadsheets, presentations, downloaded files, Word files and in Notepad format. All such small databases together form an end user database.
Now let’s have a look at some of the popular open source databases available in the market.
MySQL
MySQL has been in use since 1995 and is currently owned by Oracle. In addition to its open source version, there are a couple of paid editions available as well, which offer some additional features, such as cluster geo-replication and automatic scaling. We all know that MySQL has become an industry standard now, as it is compatible with almost every operating system and has been written in both C and C++. This database option is great for different international users as well, since the server can provide various error messages to the clients in a number of languages.
Pros:
- Offers a flexible privilege and password system
- Can be used even if there is no available network
- Uses host-based verification
- It consists of different libraries that can be embedded into various standalone applications
- It has security encryption for all the password traffic
- Supports servers as a separate program for the client server networked environment
Cons:
- Users feel that MySQL no longer falls under the free OS category
- It is no longer community driven, so bug fixes and patches do not happen in time
- Falls behind other similar available options due to its slow updates
PostgreSQL
PostgreSQL, also called Postgres, is basically an object-relational DBMS with much emphasis on extensibility and standards compliance. As a database server, its important functions are to securely store data and return the data or data sets in response to different requests made from other software applications. PostgreSQL can handle different workloads, ranging from that of small single-machine applications to even large Internet-facing applications with many concurrent users. It has been developed by PostgreSQL Global Development Group, and is available as free and open source software.
Pros:
- It is transactional and ACID (atomicity, consistency, isolation, durability)-compliant
- Supports updatable views and materialised views
- Functions, stored procedures, triggers, etc, can be very well used in it
- Supports concurrency with the help of a system known as MVCC (Multi Version Concurrency Control).
- Provides three levels of transaction isolation, which are: Read Committed, Repeatable Read and Serialisable
- Supports serialisability using the serialisable snapshot isolation technique
- Supports a large variety of data types like Boolean, binary, etc
Cons:
It does not have any bug tracker (whereas it supports a bug-submission form, which feeds into the pgsql-bugs mailing list), making it a bit difficult to know the status of bugs.
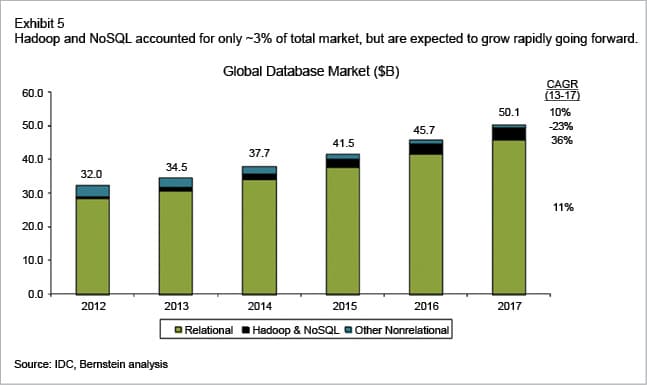
Figure 2: Global database markets at a glance
MariaDB
MariaDB is a database that is widely used by tech giants like Wikipedia, Facebook and even Google. It has been developed by various developers who worked as part of MySQL. It is basically a database server that provides drop-in replacement functionality for MySQL. Data security is one of the most significant concerns and priorities for developers of MariaDB, and almost in each of its solution releases the developers merge in all of MySQL’s security patches and also enhance the same, if required.
Pros:
- It provides real-time access to the data sets
- It supports the maximum number of core functionalities of MySQL (it is an alternative to MySQL)
- It supports high scalability with easier integration
- It provides a couple of alternate patches, storage engines and server optimisations
Cons:
- It does not provide support for the memcached interface
- The password complexity plugin is not available
- Has no optimiser trace
Choosing the best available open source database
1. Size of data: When choosing a database, we should always consider the volume of data that we need to retrieve and store as critical application data in a database. The amount of data that we can retrieve and store may vary depending on the combination of the selected data structure, and the ability of any database to differentiate between various data sets available across multiple servers and file systems. Hence, we need to choose our database by considering the overall volume of data generated by a software application at any specific rate, and also the size of data that needs to be retrieved from the database.
2. Speed and scalability: We must also gauge the speed that we require for reading and writing different sets of available data into the database—the time taken to service all the incoming reads and writes to any specific application. Some databases are designed to optimise read-heavy applications, whereas others are designed to support write-heavy solutions. Selecting a database that can handle our application’s input/output needs can really go a long way to a scalable architecture.
3. Structure of data: Structure of the data set is all about the manner in which we need to store and retrieve our data. Since an application deals with data present in diverse formats, before selecting a database we should consider picking the right data structure for storing and retrieving the data sets. If we fail to select the right data structure for persisting available data, the application may take more time to retrieve data from the database. This could also lead to more development efforts to work around any of the data issues.
4. Accessibility of data: We should also think about the number of users that may concurrently access the database in order to perform any operation on available data, and also the level of computation involved in accessing any set of data. The processing speed of software applications may get affected if the database chosen is not really good enough to handle large loads.
5. Safety and security of data: We must also check the level of security that a database provides for the data stored in it. In case of highly confidential data, we really need to have a highly secured database for the application using it. The different safety measures implemented by a database in case of any system crash or failure are an important factor that you should look at before choosing a database.
每天推荐一个 GitHub 优质开源项目和一篇精选英文科技或编程文章原文,欢迎关注开源日报。交流QQ群:202790710;电报群 https://t.me/OpeningSourceOrg
