每天推薦一個 GitHub 優質開源項目和一篇精選英文科技或編程文章原文,歡迎關注開源日報。交流QQ群:202790710;電報群 https://t.me/OpeningSourceOrg
今日推薦開源項目:《JS消息對話框插件SweetAlert2》
推薦理由:SweetAlert2是一款功能強大的純Js模態消息對話框插件。SweetAlert2用於替代瀏覽器默認的彈出對話框,它提供各種參數和方法,支持嵌入圖片,背景,HTML標籤等,並提供5種內置的情景類,功能非常強大。
![]()
簡介
SweetAlert2是SweetAlert-js的升級版本,它解決了SweetAlert-js中不能嵌入HTML標籤的問題,並對彈出對話框進行了優化,同時提供對各種表單元素的支持,還增加了5種情景模式的模態對話框。
安裝
可以通過bower或npm來安裝sweetalert2對話框插件。
|
使用
使用SweetAlert2對話框需要在頁面中引入sweetalert2.min.css和sweetalert2.min.js文件,為了兼容IE瀏覽器,還需要引入promise.min.js文件。
<link rel="stylesheet" type="text/css" href="path/to/sweetalert2/dist/sweetalert2.min.css"> <script src="path/to/sweetalert2/dist/sweetalert2.min.js"></script> <!-- for IE support --> <script src="path/to/es6-promise/promise.min.js"></script>
基本使用:
基本的使用方法是使用通過swal()來彈出一個對話框。
swal('hello world!');
如果要彈出一個帶情景模式的對話框,情景模式類型可以如下在第三個參數中設置。
swal('Oops...', 'Something went wrong!', 'error');
swal(...)會返回一個Promise<boolean>對象,該Promise對象中then方法中的isConfirm參數的含義如下:
- true:代表Confirm(確認)按鈕。
- false:代表Cancel(取消)按鈕。
- undefined:代表按下Esc鍵,點擊取消按鈕或在對話框之外點擊。
模型對話框的類型
sweetalert2提供了5種情景模式的對話框。

效果演示
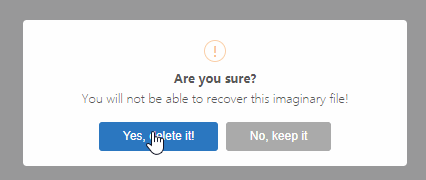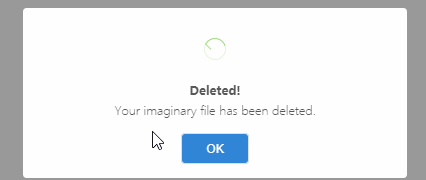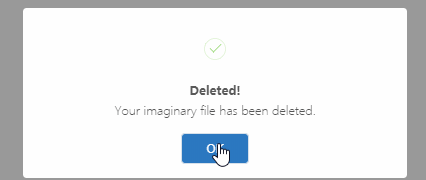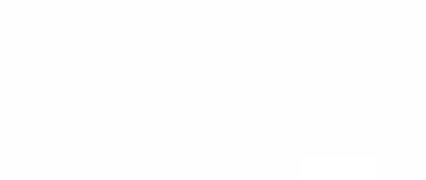
嵌入函數的彈窗
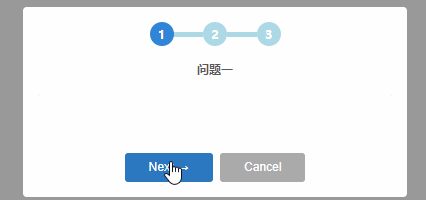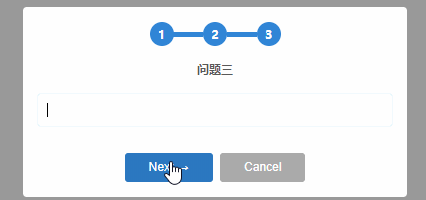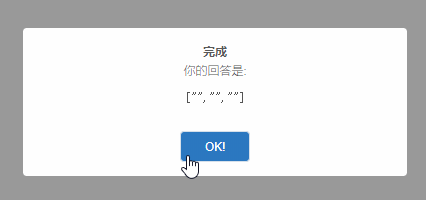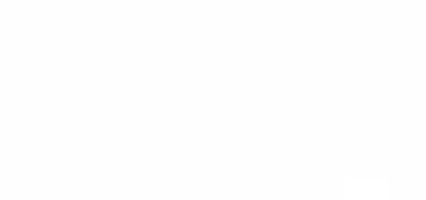
鏈式彈窗示例
通過SweetAlert2還可以實現各種效果,如定時關閉,自定義彈窗的大小,背景,加入動畫等等,更多的效果演示和具體操作可以訪問SweetAlert2的官網
鏈接:https://sweetalert2.github.io/
瀏覽器兼容性
| IE11 * | Edge | chrome | 火狐 | Safari | 歐朋 | Android瀏覽器* | UC瀏覽器* |
| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
*應包括ES6 Promise polyfill,請參閱使用示例。
需要注意的是SweetAlert2 不且將不提供任何形式的IE10和更低的支持或功能。
相關的github項目
- avil13 / vue-sweetalert2 - Vue.js包裝
- softon / sweetalert - Laravel 5 Package
- alex-shamshurin / sweetalert2-react - 反應組件
今日推薦英文原文:《A brief introduction to two data processing architectures — Lambda and Kappa for Big Data》
原文作者:
A brief introduction to two data processing architectures — Lambda and Kappa for Big Data
Big Data, Internet of things (IoT), Machine learning models and various other modern systems are becoming an inevitable reality today. People from all walks of life have started to interact with data storages and servers as a part of their daily routine. Therefore we can say that dealing with big data in the best possible manner is becoming the main area of interest for businesses, scientists and individuals. For instance an application launched for achieving certain business goals will be more successful if it can efficiently handle the queries made by customers and serve their purpose well. Such applications need to interact with data storage and in this article we』ll try to explore two important data processing architectures that serve as the backbone of various enterprise applications known as Lambda and Kappa.
The rapid growth of social media applications, cloud based systems, Internet of things and an unending spree of innovations has made it important for a developer or a data scientist to take well calculated decisions while launching, upgrading or troubleshooting an enterprise application. Although it has been widely accepted and understood that using a modular approach to build an application has multiple advantages and long term benefits, the pursuit for selecting the right data processing architecture still keeps putting question marks in front of many proposals related to existing and upcoming enterprise software. Although there are various data processing architectures being followed around the globe these days let』s investigate the Lambda and Kappa architectures in detail and find out what makes each of them special and in what circumstances one should be preferred over another.
Lambda Architecture
Lambda architecture is a data processing technique that is capable of dealing with huge amount of data in an efficient manner. The efficiency of this architecture becomes evident in the form of increased throughput, reduced latency and negligible errors. While we mention data processing we basically use this term to represent high throughput, low latency and aiming for near-real-time applications. Which also would allow the developers to define delta rules in the form of code logic or natural language processing (NLP) in event-based data processing models to achieve robustness, automation and efficiency and improve the data quality. Moreover, any change in the state of data is an event to the system and as a matter of fact it is possible to give a command, queried or expected to carry out delta procedures as a response to the events on the fly.
Event sourcing is a concept of using the events to make prediction as well as storing the changes in a system on the real time basis a change of state of a system, an update in the databases or an event can be understood as a change. For instance if someone interact with a web page or a social network profile, the events like page view, likes or Add as a Friend request etc… are triggering events that can be processed or enriched and the data stored in a database.
Data processing deals with the event streams and most of the enterprise software that follow the Domain Driven Design use the stream processing method to predict updates for the basic model and store the distinct events that serve as a source for predictions in a live data system. To handle numerous events occurring in a system or delta processing, Lambda architecture enabling data processing by introducing three distinct layers. Lambda architecture comprises of Batch Layer, Speed Layer (also known as Stream layer) and Serving Layer.
1. Batch layer
New data keeps coming as a feed to the data system. At every instance it is fed to the batch layer and speed layer simultaneously. Any new data stream that comes to batch layer of the data system is computed and processed on top of a Data Lake. When data gets stored in the data lake using databases such as in memory databases or long term persistent one like NoSQL based storages batch layer uses it to process the data using MapReduce or utilizing machine-learning (ML) to make predictions for the upcoming batch views.
2. Speed Layer (Stream Layer)
The speed layer uses the fruit of event sourcing done at the batch layer. The data streams processed in the batch layer result in updating delta process or MapReduce or machine learning model which is further used by the stream layer to process the new data fed to it. Speed layer provides the outputs on the basis enrichment process and supports the serving layer to reduce the latency in responding the queries. As obvious from its name the speed layer has low latency because it deals with the real time data only and has less computational load.
3. Serving Layer
The outputs from batch layer in the form of batch views and from speed layer in the form of near-real time views are forwarded to the serving layer which uses this data to cater the pending queries on ad-hoc basis.
Here is a basic diagram of what Lambda Architecture model would look like:
Let』s translate that to a functional equation which defines any query in big data domain. The symbols used in this equation are known as Lambda and the name for the Lambda architecture is also coined from the same equation. This function is widely known to those who are familiar with tidbits of big data analysis.
Query = λ (Complete data) = λ (live streaming data) * λ (Stored data)
The equation means that all the data related queries can be catered in the Lambda architecture by combining the results from historical storage in the form of batches and live streaming with the help of speed layer.
Applications of Lambda Architecture
Lambda architecture can be deployed for those data processing enterprise models where:
- User queries are required to be served on ad-hoc basis using the immutable data storage.
- Quick responses are required and system should be capable of handling various updates in the form of new data streams.
- None of the stored records shall be erased and it should allow addition of updates and new data to the database.
Lambda architecture can be considered as near real-time data processing architecture. As mentioned above, it can withstand the faults as well as allows scalability. It uses the functions of batch layer and stream layer and keeps adding new data to the main storage while ensuring that the existing data will remain intact. Companies like Twitter, Netflix, and Yahoo are using this architecture to meet the quality of service standards.
Pros and Cons of Lambda Architecture
Pros
- Batch layer of Lambda architecture manages historical data with the fault tolerant distributed storage which ensures low possibility of errors even if the system crashes.
- It is a good balance of speed and reliability.
- Fault tolerant and scalable architecture for data processing.
Cons
- It can result in coding overhead due to involvement of comprehensive processing.
- Re-processes every batch cycle which is not beneficial in certain scenarios.
- A data modeled with Lambda architecture is difficult to migrate or reorganize.
Kappa Architecture
In 2014 Jay Kreps started a discussion where he pointed out some discrepancies of Lambda architecture that further led the big data world to another alternate architecture that used less code resource and was capable of performing well in certain enterprise scenarios where using multi layered Lambda architecture seemed like extravagance.
Kappa Architecture cannot be taken as a substitute of Lambda architecture on the contrary it should be seen as an alternative to be used in those circumstances where active performance of batch layer is not necessary for meeting the standard quality of service. This architecture finds its applications in real-time processing of distinct events. Here is a basic diagram for the Kappa architecture that shows two layers system of operation for this data processing architecture.
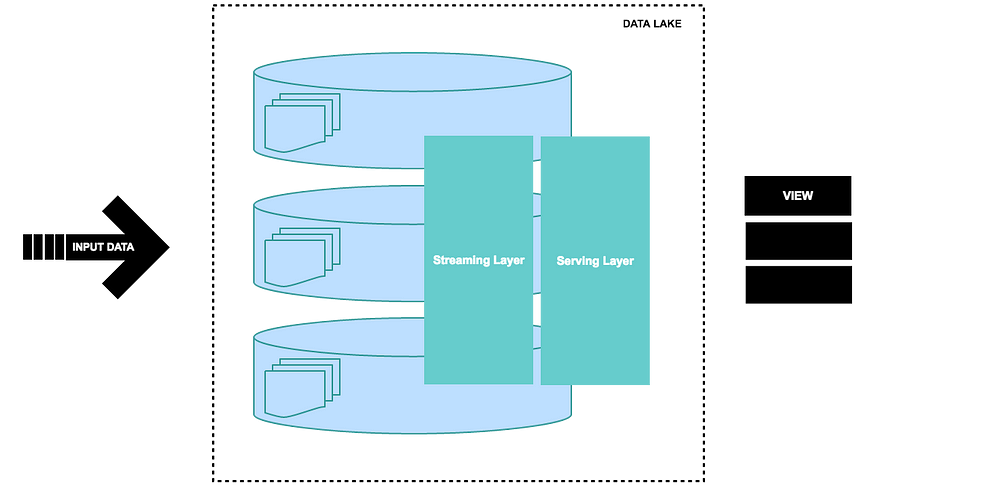
Let』s translate the operational sequencing of the kappa architecture to a functional equation which defines any query in big data domain.
Query = K (New Data) = K (Live streaming data)
The equation means that all the queries can be catered by applying kappa function to the live streams of data at the speed layer. It also signifies that that the stream processing occurs on the speed layer in kappa architecture.
Applications of Kappa architecture
Some variants of social network applications, devices connected to a cloud based monitoring system, Internet of things (IoT) use an optimized version of Lambda architecture which mainly uses the services of speed layer combined with streaming layer to process the data over the data lake.
Kappa architecture can be deployed for those data processing enterprise models where:
- Multiple data events or queries are logged in a queue to be catered against a distributed file system storage or history.
- The order of the events and queries is not predetermined. Stream processing platforms can interact with database at any time.
- It is resilient and highly available as handling Terabytes of storage is required for each node of the system to support replication.
The above mentioned data scenarios are handled by exhausting Apache Kafka which is extremely fast, fault tolerant and horizontally scalable. It allows a better mechanism for governing the data-streams. A balanced control on the stream processors and databases makes it possible for the applications to perform as per expectations. Kafka retains the ordered data for longer durations and caters the analogous queries by linking them to the appropriate position of the retained log. LinkedIn and some other applications use this flavor of big data processing and reap the benefit of retaining large amount of data to cater those queries that are mere replica of each other.
Pros and Cons of Kappa architecture
Pros
- Kappa architecture can be used to develop data systems that are online learners and therefore don』t need the batch layer.
- Re-processing is required only when the code changes.
- It can be deployed with fixed memory.
- It can be used for horizontally scalable systems.
- Fewer resources are required as the machine learning is being done on the real time basis.
Cons
Absence of batch layer might result in errors during data processing or while updating the database that requires having an exception manager to reprocess the data or reconciliation.
Conclusion
In short the choice between Lambda and Kappa architectures seems like a tradeoff. If you seek you』re an architecture that is more reliable in updating the data lake as well as efficient in devising the machine learning models to predict upcoming events in a robust manner you should use the Lambda architecture as it reaps the benefits of batch layer and speed layer to ensure less errors and speed. On the other hand if you want to deploy big data architecture by using less expensive hardware and require it to deal effectively on the basis of unique events occurring on the runtime then select the Kappa architecture for your real-time data processing needs.
每天推薦一個 GitHub 優質開源項目和一篇精選英文科技或編程文章原文,歡迎關注開源日報。交流QQ群:202790710;電報群 https://t.me/OpeningSourceOrg

Very good written post. It will be beneficial to anybody who employess
it, as well as myself. Keep up the good work – for sure i will check out more posts.
When I initially commented I clicked the "Notify me when new comments are added" checkbox and now each
time a comment is added I get several e-mails with the same comment.
Is there any way you can remove me from that service?
Thanks a lot!
We can hunt for, andd discover, any information inside of seconds, we
are able to connect to our buddies and distant acquaintances on a amount of social networks, we
could broadcast our feeling towards the whole world, and wee are able to invite the crooks to rrad or
view our opinions (and acquire bought it for).
Search engines have made everything tthe greater easier for
individuals to find business, however it is very important to businesses to being visible during these spaces to ensure to draw potential
customers. Business people make use of this space to promoting their goods and services.
cheers a great deal this site is usually elegant as well as informal
many thanks considerably this excellent website is definitely formal and
laid-back
This paragraph provides clear idea for the new users of blogging, that in fact how to do
running a blog.
Good post. I certainly appreciate this website.
Continue the good work!
I was recommended this website by my cousin. I am not sure whether this post is written by him as nobody else know such detailed about my difficulty.
You're amazing! Thanks!
I am genuinely grateful to the owner of this web site
who has shared this fantastic article at at this time.
Great delivery. Outstanding arguments. Keep up the good effort.
I simply couldn't leave your site before suggesting
that I extremely enjoyed the usual info a person provide for your visitors?
Is going to be again continuously to inspect new posts
I used to be able to find good information from your articles.
Hi to every single one, it's genuinely a good for me to go to
see this website, it consists of valuable Information.
I have been absent for a while, but now I
remember why I used to love this site. Thanks, I will
try and check back more frequently. How frequently
you update your web site?
Heya i am for the first time here. I came across this board
and I to find It truly helpful & it helped me out much.
I'm hoping to give something back and aid others like you aided me.
Thanks for finally writing about >2018年3月22日:開源日報第14期 – 開源工場 <Loved it!
You can definitely see your enthusiasm in the article you
write. The world hopes for even more passionate writers such as you who are not afraid to say how they believe.
All the time go after your heart.
It's great that you are getting thoughts from this article
ass wel as from our discussion made here.
@2009: Thank you!