今日推荐开源项目:《模拟器 goboy》
今日推荐英文原文:《Code, Archeology, and Line Breaks》
元旦假期:下一期开源日报将在 2021 年 1 月 4 日恢复更新

今日推荐开源项目:《模拟器 goboy》传送门:项目链接
推荐理由:goboy 是使用 go 语言编写的 GameBoy 模拟器,支持大部分 GB 游戏和部分 CGB 游戏。目前还在开发中,如果对 GO 语言有一定基础并且对该模拟器感兴趣的话,欢迎在 GitHub 上投稿。
今日推荐英文原文:《Code, Archeology, and Line Breaks》作者:Donovan So
原文链接:https://medium.com/better-programming/code-archeology-and-line-breaks-86b38da32ca7
推荐理由:虚拟的数据和实际的现实生活密不可分,从来源于老式打字机的回车换行符
\r\n ,到电脑中的“废纸篓”图标,再到 GitHub 的北极归档计划。未来的人们将从我们的代码中学到什么?
Code, Archeology, and Line Breaks
Did you know \r and \n are remnants of typewriters?

(Photo by Bernard Hermant on Unsplash.)Have you ever wondered how a new line is stored on a computer? You know, what happens when you hit “enter” in a text editor?
On Windows, a new line is stored as the weird sequence
\r\n. For example, the following text:
Hello
World!
Is actually stored as
Hello\r\nWorld! on a Windows system.
It turns out \r is called a carriage return and \n is called a line feed. They are special characters that have their origins from typewriters. In the past, when people reached the end of a line on a typewriter, they pushed on a lever that did two things:
1. It returned the carriage that held the paper so the typing position was moved to the start of a line. 2. It fed a line so the typing position was moved downwards by one line.
The combination of carriage return and line feed effectively moved the current typing position to the beginning of a new line.
Today, the advent of modern computers and word processors have eliminated the need for typewriters. What’s left are the obscure special characters,
\r and \n, in our machines. My mind was blown the first time I learned about this — what a piece of human history hidden in everyday code!
Side note: Mac and Linux systems simply use the line feed character
\n instead of the more verbose sequence \r\n to represent a new line. While it is more storage-efficient, it is technically not as “historically accurate.”
There are more examples. The term “programming bug” was publicized because an actual bug once caused a machine to malfunction. The reason the programming language Fortran ignores whitespace is that people used to code on punchcards and it was easy to insert whitespace by mistake. It’s fascinating to think about how many anecdotes and patterns of human behaviors are hidden in something as mechanical and lifeless as computer software.
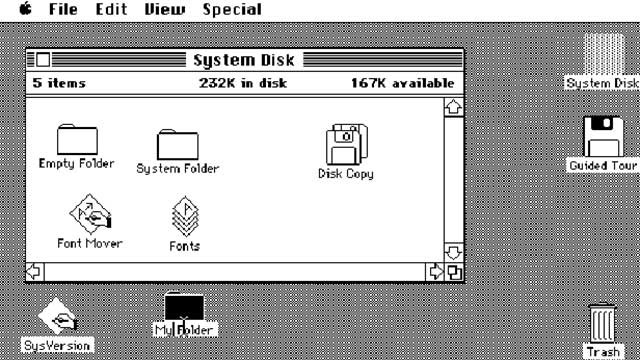
(Source: Beverly Hills Lingual Institute)On the other hand, we sometimes include elements from our real lives in our software intentionally. Designers call it a skeuomorphism, which means the incorporation of old familiar ideas into new ones. In a computer user interface (UI), folders resemble the shape of paper folders. Delete buttons look like trash bins. Save buttons look like floppy disks. The mapping from real-world objects to UI components helps people to quickly understand their functions. It gives people comfort because they are able to draw from their past experiences while interacting with new technologies. Skeuomorphism is most helpful during the initial transition period to new technologies, but when people eventually get used to the new tech, it loses its purpose. All that remain are legacy designs that have recognizable meanings, but not origins (I’m sure not everyone reading this knows what a floppy disk is).
In 2020, GitHub, the largest software hosting service on the planet, announced the Archive Program. One of its initiatives is to archive all existing code repositories into a vault deep in an Arctic mountain. I suspect that in a hundred years’ time, archeologists will no longer study bones and ancient artifacts but our software. They will no longer dig for fossils but hard drives. They will no longer inspect cave paintings but pieces of lasered glass (yes, that’s how Microsoft’s Project Silica is planning to preserve large amounts of data for over 10,000 years). What will our future generations learn about us from our code?
In a more philosophical sense, what will our future generations not learn about us? My Google search history, Amazon purchases, and Spotify playlists are used to train machine learning models that can predict my behaviors accurately. The countless images and videos on Facebook and YouTube can be used by models to identify me by my appearance, my voice, or even my walking posture.
Don’t forget the sea of texts that companies use to train their voice assistants, translation services, grammar checkers, and more. Just recently, the GPT-3 model, which is trained on over 100 billion parameters, has shown uncanny general-purpose language capabilities that rival those of real humans. It has been used to create bots that generate code from plain English, write entire blog posts from short prompts, or engage in full real-time conversations with humans.
More and more facets of our existence can now be reduced to parameters in a neural network. After we’re gone, we’ll still continue to exist as bits and numbers.
What can future generations learn about us? What’s left for future generations to learn about us? Is our unprecedented technology boom helpful for future archeologists? Does having everything laid out so nakedly take away some of its beauty? Only time will tell.
下载开源日报APP:https://openingsource.org/2579/
加入我们:https://openingsource.org/about/join/
关注我们:https://openingsource.org/about/love/
